Working with Systemic-functional Grammars: II
Exploring more realistic grammar fragments: transitivity
In this tutorial we move on to consider a fragment of English clause grammar describing the basic transitivity patterns of the main process types. We see here how the computational tools can show us the consequences of moving through the grammar network in particular ways, and also how the network can provide us with examples of the clause structures that it covers.
To start the second tutorial, we need to start the KPML program as described in the first tutorial. Here we will be working with a bigger and more realistic grammar fragment called `Transitivity’. Therefore, when you select `Load Resources’ in order to load the grammar to work with, you will need to select `Transitivity’ from the options on offer:
Then click to accept your selection as described before, confirming the selection with the next dialogue box that the program brings up. When the program has loaded these resources, start up the development window.
If you do not have TRANSITIVITY in this menu when you click, then you will have to download this grammar and put it in your machine so that the KPML program can find it. See the ‘Installing grammars’ instructions.
If you start to generate a sentence with this grammar, you will be asked to make choices from the basic transitivity and clause process type area of English grammar. Let’s say that we want to see what grammatical structure corresponds to the English clause:
John rolled the ball down the hill.
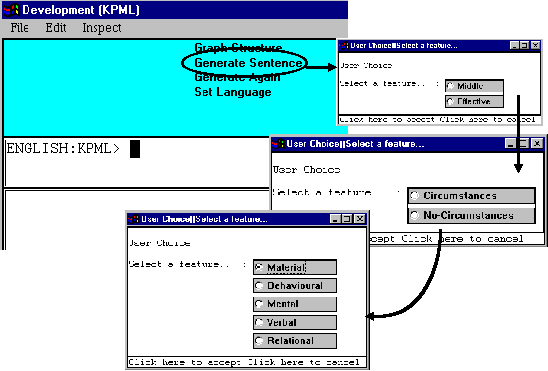
We can find this out by generating this sentence structure with our loaded grammar fragment. We click on `Generate Sentence’ to start and answer the questions concerning the applicable grammatical features that the program then asks us. The first choice point we reach is whether the clause is `middle’ or `effective’. Since some external agency is involved, the clause is `effective’ so we pick this. The next choice point is whether there are any circumstances: since there are (`down the hill’) we select `circumstances’. Finally we are asked what process type is involved: `material’, `behavioural’, `mental’, `verbal’, or `relational’; the present example is clearly `material’, so we pick this. This interaction is shown in the picture below.
After these choices have been made, a number of largely unintelligible messages appear in the Development window followed by the string generated, which consists mostly of `no realisation’. This is because the grammar fragment that we have used here only talks about clause structure, it has not said anything about what elements realize the Actors, Processes, Goals, etc. of these clauses. We will look at this part of the generation process in the next tutorial. For the moment, we are only interested in the structure that we have generated. We want to see if this corresponds to the example clause that we were considering. So, to see the structure generated, click on `Graph Structure’.
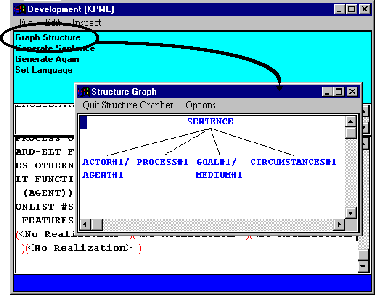
From the structure graph we see that we have a clause with four constituents: a combined Actor/Agent, a Process, a combined Goal/Medium, and some Circumstances. And this does indeed correspond to a functional analysis of our example clause: i.e.,
|
John |
rolled |
the ball |
down the hill |
|
Actor |
Process |
Goal |
Circumstances |
|
Agent |
Medium |
This shows both a transitive (Actor, Process, Goal) and an ergative (Agent, Medium) line of analysis.
If we instead wanted to find out the grammatical structure of the clause:
I like the cake.
We would need to answer the questions posed quite differently of course. This would be `middle’ and `mental’ for a start. We then also get asked questions about whether the clause is `ranged’ or not (i.e., is the process extended by some entity: here `the cake’) and what subtype of `mental’ is at issue (i.e., `perceptive’, `affective’, or `cognitive’). When we have answered these we again see a result in the Development window, which, when we look at its structure graph, corresponds to the following grammatical structure:
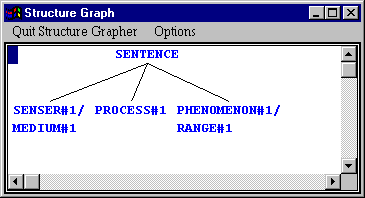
This again corresponds to our desired sentence, with the structure:
|
I |
like |
the cake |
|
Senser |
Process |
Phenomenon |
|
Medium |
Range |
As we saw in the first tutorial, we can look at the grammar that produced these structures by clicking on the Graph Region option underneath Inspect in the grey menu bar at the top of the Development window. If we do this now, then the graph will also show us the last path through the grammar that we took to generate our `liking’ sentence as follows.
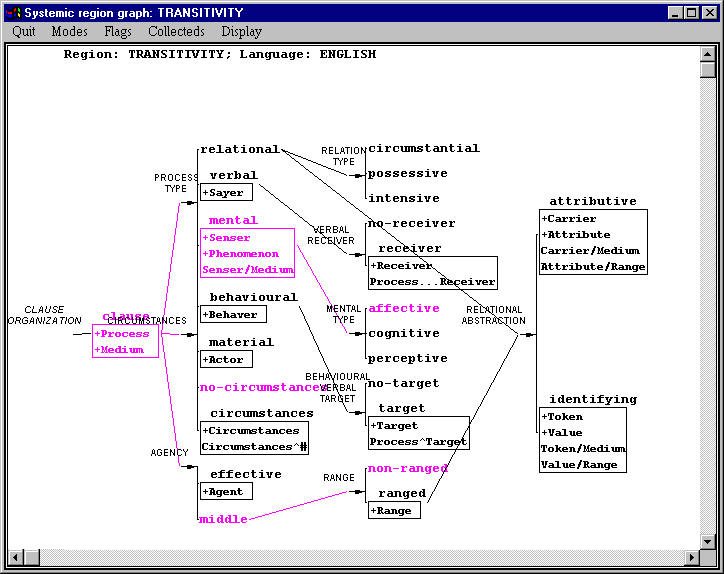
We can see that this grammar is much more complicated than the Titles example of the last tutorial. This grammar is based on the fragment for transitivity given as Figure 4.7 in Martin, Matthiessen and Painter (1997:158/9).
Note that if we follow all the paths shown in mauve (or grey in a black-and-white version of this tutorial), we do not quite appear to have enough information to generate the structures that we saw. Let’s try it.
First comes the insertion of Process and Medium (under feature `clause’), and then the insertion of Senser and its conflation with Medium under `mental’. There are no other boxes shown highlighted. But this only tells us that somewhere in the clause is a single constituent labelled Senser and Medium, and somewhere else in the clause is a Process. Some of the information in the grammar has therefore been hidden.
This information is attached to special grammatical systems called gates. These are like other systems in that they have features where realization statements are placed, but they differ from systems in that each gate only has a single feature. There is no choice involved. This is why they are not shown in this graph: only the choices that you have to make when going through the grammar are shown here. These are the choices that the grammar made you answer questions about when we were generating.
Hiding the gates can give a good overview of a grammar fragment because we can focus on just the important distinctions (i.e., choice points) that the grammar draws.
But if we want to see the full grammar, with all these hidden gates added in so that we can see the complete set of realization statements, then we can select the `toggle gate visibility’ option under the `Flags’ option on the grammar network menu bar thus:

This means that gates will no longer be hidden and the full grammar network is shown. This is now too large to quite fit on a single screen and looks quite tangled; it is shown in the picture below.
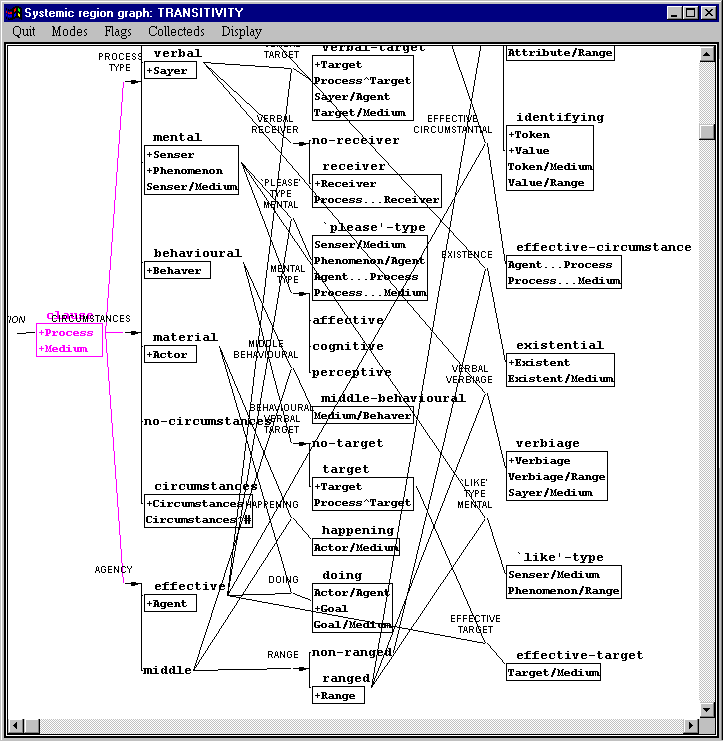
When grammars get even as large as this (and real grammars are very much larger), it starts being useful to divide them up into `regions’ so that we don’t have to look at all of the grammar at one. Here sensible regions might be for each of the process types for example. This is a resource-based way of making the grammar easier to handle. We can also choose to focus in on just those parts of the grammar that are used during generation: this is an instance-based way of making the grammar easier to handle. It is called `instance-based’ because it focuses on some particular instance of the grammar’s use, rather than on some aspect of the full potential that the grammar offers.
Here, then, we can choose to look at just the path through the grammar that we took while generating our last example clause. We do this by clicking somewhere unoccupied (i.e., some `white space’) on the grammar network. This brings up a further little menu of options.
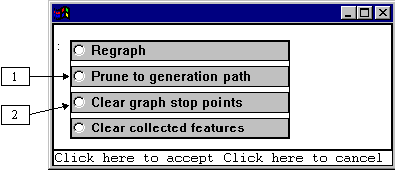
For now, we select the second of these: `prune to generation path’ (1). This brings up the following extract from the entire graph.
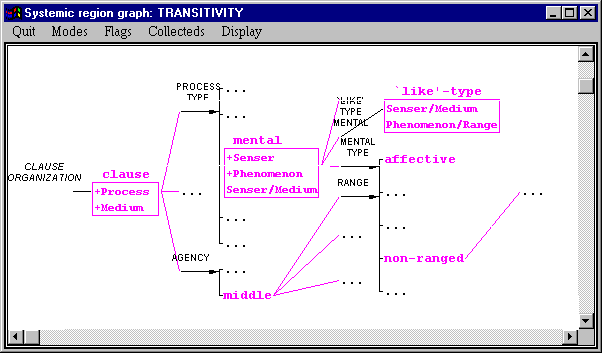
Which, as we can see, is a much more handleable quantity of information. Here we have all of the realization statements that went into constructing our example structure above. The dots (…) in the graph represent places where the grammar goes further but are not shown in the graph. You can always click on such dots in order to grow the network further at that point.
Note that we did not get asked about the feature `like-type’ that now appears precisely because it is a gate. It is this gate that has the realization statements that we were missing before. If we click on the name of this gate in the network graph, then we see that it does indeed only have a single feature. Gates like this have two main purposes. First, they can group together realization statements that would otherwise have to be written at several different places around the grammar network. And, second, they allow us to write realization statements that only apply if some combination of features apply. This is the case here where we can see that the feature `like’-type is only activated when we have previously selected both features `mental’ and `ranged’. Either of these features by itself is not sufficent to trigger this gate.

To see the entire grammar again, go back to the network graph and select `Clear Graph Stop Points’ from the menu that we used above (2). In general, you can choose to stop looking at any part of the network by clicking with the right mouse button on any node in the graph and selecting from the menu that appears `Stop Graph Here’. In general, clicking left with the mouse will do some action, while clicking right will bring up a menu of options that apply to the particular object that you clicked on. The option we used above of pruning the graph to current generation path is just a shorthand that makes the program go through all the systems and features in the graph and says `stop here’ if they are not on the path we last took through the grammar.
You should now be able to find out the grammatical structure of a wide range of clauses in English. For example, what structures do the following have?
It might be that not all of the features in the grammar are self-explanatory. This is very likely to be the case when a grammar gets larger or if you are not familiar with all aspects of the description. But here too the network organization can be of use.
As an example, let’s presume that the feature `like’-type is not at all clear. We can obtain more information about this system by clicking with the right mouse button on a system or feature name shown in a system network graph. . In this case you will see the following menu.
Selecting the `show examples with feature’ option will make the program look to see if it has any examples of the feature being used. The examples are stored as part of the resources that you loaded at the beginning of this session. In this case, the following information gets brought up.
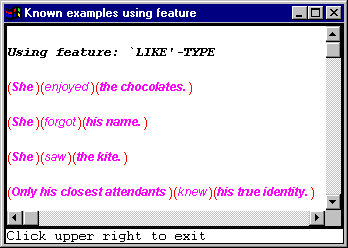
That is, all of these examples select the feature `like’-type in their generation. You could contrast this with the feature `please’-type that can also be seen in the full grammar if we were just looking at mental clauses (which you could look at, for example, by setting stop points in the grammar as described above):
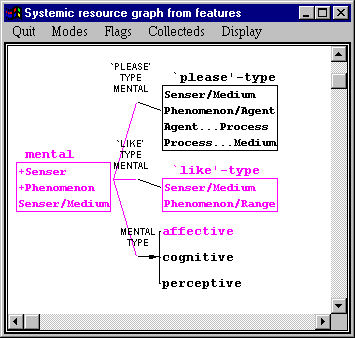
Clicking right on the feature `please’-type and selecting examples brings up the following information.
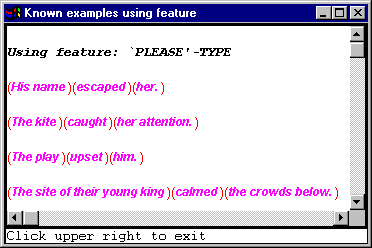
And so, by comparing these two sets of clauses you might be able to work out better what the particular difference between these features is.
If you need further information, then you can also inspect the grammatical structure of any of these example clauses that are shown. So we could compare, for example, the clause `The kite caught her attention’ from this last information box with the clause `She saw the kite’ from the previous one. You obtain the grammatical structure by moving the mouse so that all of the clause is `boxed’ and clicking with the right mouse button. This brings up a further menu, from which you select the option `Graph Corresponding Constituent and Below’.
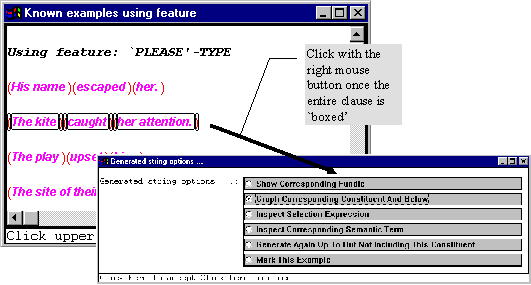
We can do this for both examples as suggested and this gives us the following two structures. Remember that you have to close new windows before you can go back and use older ones.
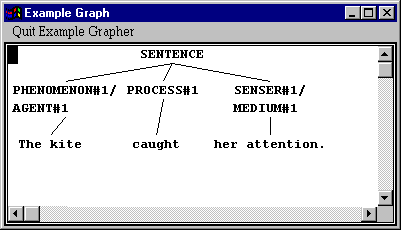
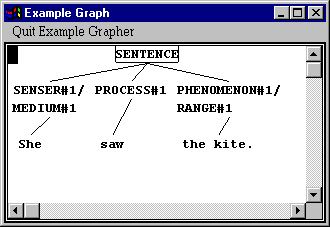
So here we can see that the major difference is in the association of Senser and Phenomenon with different `ergative’ functions: in the `please’-type the Phenomenon is an Agent, whereas in the `like’-type, the Phenomenon is a Range. In both cases, however, the Senser remains Medium. This corresponds to the realization statements that we saw in the networks above.
We can also use these structures to compare exactly which paths through the grammar were taken. Positioning the mouse on the top node `Sentence’ and clicking left, brings up the following menu.
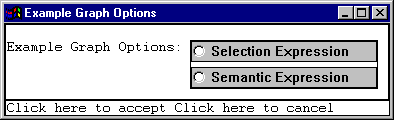
The `semantic expression’does not concern us yet, but the first option, `Selection Expression’, tells us which path was taken through the grammar in order to generate the constituent we clicked on: in this case, the entire sentence or clause. Picking this option for the two structures above brings up the following two lists respectively:
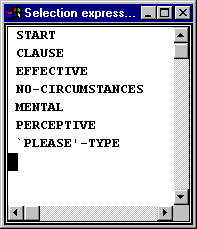
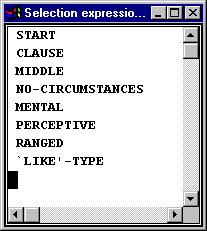
And you can then click further on each of these feature names in order to go to the system network or to find further examples, etc.
There are also places where the current grammar fragment does not cover all the clauses we might try to generate. Can you find any gaps?
Taking a sentence, clause, or other linguistic unit, and going through the network selecting linguistic features is called `coding’. One use of coding is to compile a linguistic `profile’ of some text or linguistic data, which we can then use for detailed linguistic analysis. Thus we could code some text and then loook to see how the linguistic features were distributed across that text. Another use of coding is as a way of exploring a grammar. If we do not know in advance how a grammar is organized, then we can let the generation program guide us through the questions the grammar needs to ask, looking at examples of the distinctions drawn as we go. Doing this for a range of examples gives a good sense of how a grammar is organized and what it covers.