Zaharani Ahmad (Universiti Kebangsaan Malaysia)The Phonology of Words with Monosyllabic Stems in Malay
It is generally observed that when monosyllabic stems undergo the process of affixation with verbal prefixes /məN-/ and /di-/ in Malay, two phonological alternations surface in the output forms, namely vowel lengthening (i.e. /di-pam/ → [di:pam] ‘to pump (passive)’), and schwa epenthesis (i.e. /məN-pam/ → [məŋəpam] ‘to pump (active)’). Unlike the later, the former has not been well examined and accounted for in the previous studies, and therefore the analyses missed some important generalisations about the phonology of the so-called monosyllabic stems in Malay. Previous studies suggested that the so-called monosyllabic stems are lexically disyllabic with an initial empty V-slot at the CV tier. This representation is in agreement with the basic prosodic structure of the words in the language which is normally disyllabic. This empty V-slot triggers the application of vowel lengthening and schwa epenthesis rules, and simultaneously blocks the application of visibly active rules such as nasal assimilation, nasal deletion and nasal substitution. However, based on additional data generated from DBP corpus, it is apparent that there are monosyllabic stems that do not undergo schwa epenthesis as predicted by the rule (i.e. /məN-gam/ → [məŋgam] ‘to glue’. This demonstrates that the previous analysis is inadequate and over generalised. The present study concurs that the so-called monosyllabic stems are lexically disyllabic but with an initial empty mora. In the process of syllabification, the empty mora in the rhyme can be linked either with a preceding vowel, an epenthetic schwa or a homorganic nasal.

Hans Basbøll (Sønderborg)Monosyllables and Prosody: The Sonority Syllable Model meets the Word
To understand the nature of a monosyllable, we must consider the notions of both syllable and word, a monosyllable being a syllable and a word at the same time. The focus of my presentation will be the interaction of principles of syllable structure with principles of word structure.
The starting point will be the isolated syllable, thus a prototypical monosyllable (isolability being a main criterion of wordness). I shall build upon the Sonority Syllable Model (cf. my Phonology of Danish, Oxford UP 2005: 173-247, fig. on p. 184) which derives the sonority hierarchy, in a non-circular way, from existing vs. excluded segment types through the implication:
[vocoid] implies [sonorant] implies [voiced],
which can be illustrated with a set of Euler’s circles (for the moment ignoring any aspect of time, the circles just represent universal logic of segment types):
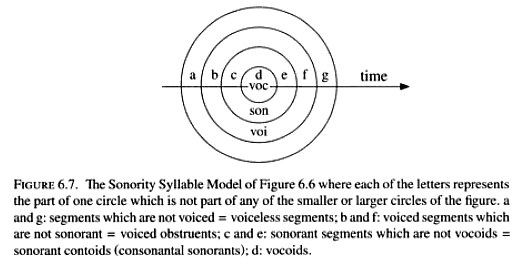
When the dimension of time is introduced into the set of concentric circles, a set of relevant order classes of phonotactics follows, predicting the order (up to the peak): voiceless segments, voiced obstruents, consonantal sonorants, glides; and the mirror-image order in the final part of the syllable.
I shall discuss what happens at the margins (i.e. edges of the word) of the isolated monosyllable, including the status of sibilants and other segments with spread glottis with respect to sonority and the word. Another issue of syllable-word interaction to be taken up is how morphological operations can affect phonotactics, as seen in Danish imperative formation (resulting in forms like afmønstr! ’discharge!’ hækl! ’crocket!’which are neither well-formed syllables nor words). I shall, furthermore, demonstrate the importance of the category of monosyllabic (as against polysyllabic) stems in word prosody.
I shall end by proposing a typology of monosyllables, according to the criteria discussed in the presentation, viz. phonotactic, morphonotactic, morphological and prosodic, departing from the Sonority Syllable Model.
Yuan-Lu Chen (National Chung Cheng University)
Lexical-Syllable Neutralization Is Banned: Evidence from Cross-Linguistic
Investigation on Nasality of Vowels
This paper examines the degree of the vowel nasalization of bilinguals, who
speak a vowel-nasality-contrastive language (Southern Min) and a vowel-nasalitynon-
contrastive language (Mandarin), to explore how contrast is preserved.
Contrast preservation has been proposed as a formal property of the grammar.
In Flemming (1995 [2002]), contrast preservation is done with Minimal Distance
(MinDist) constraints, which claims that perceptual difference between segments are
valued, suggesting that contrast preservation is done at phoneme-level. Padgett
(2003a,b) proposes a constraint, *MERGE, to preserve contrast, which states that no
word of the output has multiple correspondents in the input, suggesting contrast
preservation is done at morpheme level. In Łubowicz (2003) contrast is preserved by
comparing different mappings from underlying form to surface forms, suggesting that
contrast preservation can be done at any level, since an underlying form can be a
phoneme, syllable, or morpheme. The question is which assumption is true. In other
words, what are the compared items? This paper explores the interaction of nasality
spreading and contrast preservation in Mandarin and Southern Min, using acoustic
analysis, to explore this question.
In Taiwan, many people are bilingual of Southern Min and Mandarin. Nasality
of vowels in Southern Min is contrastive, but not in Mandarin, as shown in (1). This
bilinguality provides the possibility to do cross-linguistic investigation on nasality
within the same speaker; this setting would exclude the possibility that different
degrees of nasalization are the result of different vocal statuses of different people. I
set up phonological similar environments in Southern Min and Mandarin respectively,
which should cause nasality spreading: a vowel followed by a nasal onset, as shown
in (2); the pre-nasal vowel is the target to investigate. Since nasality on vowels is not
contrastive in Mandarin, the nasality spreading would not cancel contrasts in
Mandarin. Given this, the degree of nasality spreading in Mandarin tokens can be
seen as the result of no contrast preservation effect.
The experiment is a reading task. Two sets of reading tokens are examined: (a)
possible-merger set, and (b) non-merger set, as shown in (3) and (4). In (4) the
Southern Min token has no corresponding forms with underlyingly nasalized vowel,
implying that nasality spreading here would no cancel morpheme-contrast. In each
set, the Mandarin tokens are taken as a control condition, where there is no
preservation effect. The focus is the Southern Min tokens. The nasality of the target
vowel is quantified, employing the technique provided in Chen (1997). The result is
that in the possible-merger set, nasality of the target vowel in Southern Min is much
smaller than that in Mandarin; in the non-merger set, the target vowel is almost
equally or more nasalized. The result shows that in the possible-merger set, nasality of
the target vowel in Southern Min is preserved, but not in the non-merger set. Given
this, contrast preservation can not be done at syllable- or phoneme-level, because if so
the nasality of the target vowel in non-merger set should be preserved as well, since it
is a phoneme and syllable. The nasality-preserved Southern Min token 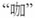 is not a
morpheme, but a lexical-syllable, for it itself standing alone expresses no semantic
meaning and serves no syntactic function. This is the level in which contrast is
preserved, a level bigger than phoneme but smaller than morpheme.
is not a
morpheme, but a lexical-syllable, for it itself standing alone expresses no semantic
meaning and serves no syntactic function. This is the level in which contrast is
preserved, a level bigger than phoneme but smaller than morpheme.

Selected References:
Chen, Marilyn Y. (1997). Acoustic correlates of English and French nasalized vowels.
Journal of the Acoustical Society of America. 102(4), 1250-2370.
Flemming, Edward (1995 [2002]). Auditory Representations in Phonology. Doctoral
dissertation, UCLA [published in 2002 by Routledge, New York].
Flemming, Edward (2004). Contrast and perceptual distinctiveness. In Hayes, Bruce,
Robert Kirchner and Donca Steriade (eds.) Phonetically-based Phonology.
Cambridge: Cambridge University Press.
Łubowicz, Anna. (2003). Contrast Preservation in Phonological Mappings. Ph.D.
dissertation, University of Massachusetts, Amherst. Amherst, MA: GLSA.
Padgett, Jaye (2003a). Contrast and post-velar fronting in Russian.
Natural Language
and Linguistic Theory
, 21(1), 39-87.
Padgett, Jaye (2003b). The emergence of contrastive palatalization in Russian. In
Holt, Eric(ed.) Optimality Theory and Language Change. Dordrecht: Kluwer
Academic Press. 307-335.
Mina Dan (University of Calcutta, India)A Sonority Survey of the Monosyllables in Bangla
Monosyllables offer the test-field for checking legal combinations of segments in a language and, at the same time, for framing a set of laws for spotting illegal partners in that same linguistic customs. The former is accomplished by devising a template that functions as a syllable-detector while the latter by discovering pertinent constraints or template conditions that reflect the phonotactics of the language.
Tools like template and template conditions have their foundation chiefly on the three aspects of sonority, viz. sonority value, sonority scale, sonority hierarchy and sonority sequencing generalization, as is shown in the phonological tradition.
The present paper treats the monosyllables in Bangla, an Eastern Indic language, in terms of their:
- canonical patterns
- internal structures
- correlation between the phonetic peak and phonological nucleus
- template
- template conditions
- phonotactic implications
In the course of analysis the paper exploits the sonority factor to its fullest extent and also points out the limitations of the sonority scale as proposed in the literature as a universal yardstick.
Christian T. DiCanio (Berkeley, U.S.A.)Consonant length in monosyllables: phonetics and diachrony
Cross-linguistically, phonological contrasts in consonant length tend to be restricted to wordmedial position (Dmitrieva, 2009; Ham, 2001; Muller, 2001). Where geminate consonants contrast with singletons word-initially, they usually also contrast word-medially. For instance, of the 29 known languages with word-initial geminates surveyed by Muller (2001), only five do not permit consonant length contrasts word-medially: Ngada, Nhaheun, Pattani Malay, Sa’ban, and Yapese. In each of these languages, geminates may surface in words which vary in length. However, in Itunyoso Trique, a MixtecanlanguageundescribedatthetimeofMuller’s work, theconsonantlength contrast surfaces only in the word-initialposition of monosyllabic words. This paper examines the phonology, phonetics, and diachrony of the singleton-geminate contrast in Trique monosyllables.
Table 1: Singleton–Geminate Contrast
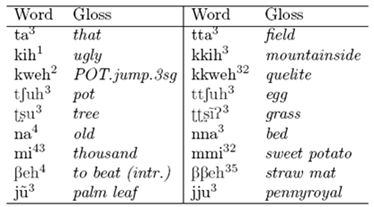
Table 1 shows the singleton–geminate contrast in Itunyoso Trique (where numbers indicate tone). Geminate obstruents frequently surface with abrupt glottal spreading which precedes consonant closure, resulting in audible preaspiration (DiCanio, 2008). Singleton obstruents never surface with preaspiration and may undergo partial voicing assimilation in running speech. Unlike wordinitial geminate obstruents in Pattani Malay (Abramson, 1986, 1991, 2003), word-initial geminate obstruents in Trique are not distinguished by differences in intensity or consonant strength, but by differences in glottal manner features and duration.
Table 2: Diachrony of Gemination

This contrast arose in Trique monosyllables through three converging and regular processes of sound change: syncope, stress-conditioned lengthening, and cluster simplification. As the general shape of words Mixtecan languages is the bisyllabic couplet (Hinton, 1991; Macaulay, 1996), the loss of penultimate syllable vowels created a complex set of onset clusters in monosyllables, which were subsequently simplified. Further evidence for a process of vowel syncope is found in the neighboring Copala Trique language (Hollenbach, 1984, 2004), which has a larger set of onset clusters among monosyllabic roots. A sample set of Proto–Mixtecan and Proto–Trique forms is given in Table 2, following the set of sound changes in Rensch (1976). The loss of pre-tonic vowels in Proto-Trique, coupled with pre-stress consonant lengthening led to the genesis of a geminate-singleton contrast in word-initial position. The unique phonology of monosyllables in Trique arises from regular processes of sound change in a language family with primarily bisyllabic roots.
References:
Abramson, A. S. (1986). The perception of word-initial consonant length: Pattani Malay. Journal of the International Phonetic Association, 16:8–16.
Abramson, A. S. (1991). Amplitude as a cue to word-initial consonant length: Pattani Malay. In Proceedings of the 12th International Congress of Phonetic Sciences, volume 3, pages 98–101. Université de Provence, Aix-en-Provence.
Abramson, A. S. (2003). Acoustic cues to word-initial stop length in Pattani Malay. In Proceedings of the 15th International Congress of the Phonetic Sciences, pages387–390.Universidadautónoma de Barcelona.
DiCanio, C. T. (2008). The Phonetics and Phonology of San Martín Itunyoso Trique. PhD thesis, University of California, Berkeley.
Dmitrieva, O. (2009). Geminate typology and perception of consonant length. Paper presented at the 82nd Annual Meeting of the Linguistics Society of America.
Ham, W. H. (2001). Phonetic and Phonological Aspects of Geminate Timing. Outstanding Dissertations in Linguistics. Routledge.
Hinton, L. (1991). An Accentual Analysis of Tone in Chalcatongo Mixtec. In Redden, J. E., editor, Papers from the American Indian Languages Conferences Held at the University of California, Santa Cruz, Occasional Papers on Linguistics, No.16, pages 173–182. Carbondale: Southern Illinois University.
Hollenbach, B. E. (1984). The Phonology and Morphology of Tone and Laryngeals in Copala Trique.
PhD thesis, University of Arizona.
Hollenbach, B. E. (2004). Vocabulario breve del triqui de San Juan Copala. SIL International.
Macaulay, M. (1996). A Grammar of Chalcatongo Mixtec, volume 127 of
University of California
Publications in Linguistics
. University of California Press.
Muller, J. S. (2001). The Phonology and Phonetics of Word-Initial Geminates. PhD thesis, The Ohio State University.
Rensch, C. R. (1976). Comparative Otomanguean Phonology. Number 14 in Language Science Monograph. Bloomington: Indiana University.
Igor Dreer (Beer Sheva, Israel)The Human Factor of Economy of Effort Crosslinguistically: Contrastive Analysis of the Phonotactic Distribution of Phonemes in French and Byelorussian Monosyllabic Words
This paper presents a contrastive analysis of the phonotactic distribution of phonemes in French and Byelorussian monosyllabic words. The choice of monosyllabic words avoids concomitant factors such as syllable stress and vowel reduction in non-stressed syllables. The analysis is based on the theory of Phonology as Human Behavior (PHB), developed by Diver (1979) in an analysis of initial consonant clusters in English. Its findings have been extended to the combinations of vowels and consonants in other languages (cf. Tobin 1997: 49). The paper starts with two assumptions: a) that language is a communicative device and b) that language is an instance of human behavior. Since communication is based on the production of phonemes, as the smallest distinct sounds, the latter are the basic units of the analysis. The fact that language is an instance of human behavior implies the human beings’ desire to look for economy of effort, inherent in human nature. This means that the degree of the control of the vocal tract musculature, required to articulate phonemes, may influence their distribution. Throughout this paper, I will compare French and Byelorussian with respect to a direct connection between the effort that speakers make to control the articulators, involved in the production of phonemes, and the favorings or the disfavorings of these phonemes in various phonotactic distributions. I will show that phonemes and clusters requiring more effort and a greater degree of control are generally disfavored in both languages. However, certain phonemes and clusters create more communicative oppositions and, therefore, justify a greater effort necessary for their production. Frequency counts will validate these statements.
References:
Diver, W. (1979). “Phonology as Human Behavior”. In: D. Aaronson and R.W. Rieber, (eds), Psycholinguistic Research: Implications and applications. Hillsdale, NJ: Lawrence Erlbaum, 161-186.
Tobin, Y. (1997). Phonology as Human Behavior: Theoretical implications and clinical applications. Durham, NC: Duke University Press.
Gertraud Fenk-Oczlon (Universität Klagenfurt)Monosyllabism from a systemic typological perspective
Monosyllabism has since long been considered as a typologically relevant phenomenon. Monosyllabic languages are often opposed to polysyllabic languages, although one has to take into account that monosyllabism is a gradual phenomenon and that clear-cut classifications are not possible. In this talk I shall discuss monosyllabism from a systemic typological perspective and try to show that monosyllabism interacts in a systematic way with other components of the language system, e.g. phonology and semantics.
- The tendency to monosyllabism is associated with a tendency to phonological complexity:
A previous study (Fenk-Oczlon & Fenk 2008) has revealed significant positive cross-linguistic correlations between the number of monosyllables, the number of syllable types, syllable complexity, and phonemic inventory size. The data were collected and calculated from Menzerath’s (1954) description of 8 Indo-European languages (English, German, Romanian, Croatian, Catalan, Portuguese, Spanish and Italian).
We have then (work in progress) started to look whether these correlations could be reproduced using a somewhat extended sample of languages including also non-Indo-European languages and using a different method, i.e. texts instead of language descriptions. Therefore we compared, in a first step, 11 languages with respect to their proportion of monosyllables in text. The “text” was a controlled set of 22 simple sentences that were translated by native-speakers into their mother tongue. The results so far: English with 73 monosyllables exhibits the highest proportion of monosyllables, followed by Dutch, German, Mandarin, Vietnamese, Thai, Cantonese, Malagasy, Russian, Karo Batak and Marrangu which showed only 2 monosyllables. The correlation between the average number of monosyllables and average syllable complexity (r= + .69) showed the expected sign and was significant (p < .05) despite the small sample of only 11 data pairs.
Further interactions will be discussed between monosyllabism and phenomena such as
- a tendency to homophony and polysemy,
- a tendency to a high proportion of idioms, formulaic speech and rigid word order, and,at least in non-tone languages,
- a tendency to stress-timed rhythm.
References:
Fenk-Oczlon, G. & Fenk, A. (2008). Complexity trade-offs between the subsystems of language. In M. Miestamo, K. Sinnemäki & F. Karlsson (eds.) Language Complexity: Typology, contact, change, 43–65. Amsterdam/Philadelphia: John Benjamins.
Menzerath, P. (1954). Die Architektonik des deutschen Wortschatzes. Hannover/Stuttgart: Duemmler.
Franck Floricic (Université de Paris III -Sorbonne Nouvelle & LPP)Lucia Molinu (Université de Toulouse II -Le Mirail & BCL)On some Romance Monosyllabic Imperatives: frequency effects, markedness, or else?
Imperatives have long been neglected as a category, probably due to their speech-rooted character, a feature which has long contributed to leave them outside morphological and syntactical research. Typological studies have however been proposed on recent times (see Khrakovskij (2001), Aikhenvald (to appear)) which offer an overall picture of the properties of this category. The aim of this contribution is to analyze the case of a sub-class of Romance imperatives, namely the allomorphic reduced imperatives some of which are presented in (1):
| French |
Italian |
écoute > coute ‘listen!’
attends > tends ‘wait!’
|
dici > di’ ‘say!’
tieni > tiè ‘hold!’
ascolta > asco’ ‘listen!’
togli > to’ ‘take!’
guarda > gua’ ‘look!’
|
| Sardinian |
Spanish |
nara > na’ ‘say’
mira > mi’ ‘look!’
tocca > to’ ‘go!’
tene > te’ ‘hold’
|
toma > to’ ‘take!’
mira > mi’ ‘look!’
|
It will be asked whether the monosyllabic shape of some of these reduced imperatives is due to frequency effects, a thesis defended among others by Manczak (2004). Needless to say, it has long been recognized that frequency can lead to drastic phonetic reductions. Friedrich August Pott (1852: 315) assumed for instance that the aberrant phonetic evolution of latin ‘ambulare’ in the romance languages is due to ‘häufigkeit des gebrauchs’. This analysis, applied to imperatives, was already proposed by Schuchardt (1889) and Curtius (1886) (see Manczak (2008)). It will be shown that monosyllabic imperatives and vocatives owe their reduction to another parameter: they belong to the “appeal sphere”: this speech-rooted feature is not only responsible for the reduction of these forms; it is responsible as well for its “marked” status. The markedness of imperatives and vocatives will be discussed, and it will be shown that it cannot be reduced to frequency effects (contra Haspelmath).
References:
Aikhenvald, Alexandra (to appear), Imperatives and commands. OUP, Oxford
Curtius, Georg (1886), Principles of Greek Etymology. John Murray, London
Floricic, Franck (2002), « La morphologie du Vocatif: l'exemple du sarde », Vox Romanica 61. pp.151-177
Floricic, Franck, Molinu Lucia (2003), « Imperativi ‘monosillabici’ e ‘Minimal Word’ in italiano ‘standard’ e in sardo », in Actes du XXXV Congresso internazionale di Studi della SLI. "Il verbo italiano -Approcci diacronici, sincronici, contrastivi e didattici" (Paris, 20–22 septembre 2001). Bulzoni, Roma. pp.343-357
Haspelmath Martin (2006), «Against markedness (and what to replace it with)», Journal of linguistics 42/1, pp.25-70
Khrakovskij, Victor. S. (2001) (ed.), Typology of Imperative Constructions. LINCOM Studies in Theoretical Linguistics 09.
Mańczak, Witold (2004), « Certaines formes de l’impératif en italien et en sarde », in M. Świątkowska, R. Sosnowski, I. Piechnik (eds.), Maestro e Amico. Miscellanea in onore di Stanisław Widłak. Mistrz i Przyjaciel. Studia dedykowane Stanisławowi Widłakowi. Wydawnictwo UJ, Kraków. pp.231-234
Manczak, Witold (2008), Linguistique générale et linguistique indo-européenne. Polska Akademia Umieje_tnosci, Wydzial Filologiczny, Kraków
Pott, Friedrich A. (1852), « Plattlateinisch und romanisch », Zeitschrift für Vergleichende Sprachforschung 1. pp. 309-350
Schuchardt, Hugo (1889), « Romanische Etymologien », Zeitschrift für Romanische Philologie 13. pp.525-553
Nian Liu (University of Hawaii)Dan X. Hall (University of Hawaii)In Defense of Chinese and Vietnamese Morphology
It has long been the position held by learned linguists that Chinese and Vietnamese are
examples of languages which are ‘light’ on morphology (Nguyen, 1997; Bauer, 2003). It is
argued that they are so-called isolating languages with very little evidence of the typical word
forming processes found in the bulk of the world’s other languages. We believe this premise is
a challengable notion. It has likely been motivated by the myth of mono-syllabicity and by the
apparent difficulty on the part of speakers, both native and otherwise, to sufficiently identify
what is considered an actual word in these languages.
In this regard, the overall intent of this paper is two-fold: 1) to examine in detail the
various word-form types that prevail in Chinese and Vietnamese indicating how they conform
or depart from the accepted typology of word-building processes; and 2) to compile a taxonomy
of compounds in these languages which seems to be the premier morphological structure
occuring in both, thus illustrating the variety and richness of their morphology.
To guide our exploration into Chinese and Vietnamese morphology we have chosen to
use Laurie Bauer’s morphological process classification system as a model (Bauer, 2003). With
this system, Bauer divides all the recognized morphological phenomena in the world’s
languages into nine clear and distinct categories. He does this without resorting to an arbitrary
typology involving uneccessary stereotypic terms like agglutinating and fusional, which would
otherwise be antithetical to our purposes. This classification system serves as a ‘linguistic
spreadsheet’ for our study.
We consider each of the nine sub-division (see 1-9) and determine to what extent
Chinese and/or Vietnamese include entries in their respective lexicons which conform to the
morphological archetype of that category. Furthermore, we conclude each category with a score
of relative productivity. In this way, when evidence is found for word-forms that fit the
description of a given morphological process, we assign our target languages a productivity
value on a five-point scale, indicating whether they are 1) Highly productive, 2) Moderately
productive, 3) Marginally productive, 4) Rarely productive or 5) Non-productive. This
weighted scheme, although admittedly contrived and open to reinterpretation, at least helps us
in the final analysis to determine whether Chinese or Vietnamese should be considered in the
ranks of morphologically endowed languages.
After a brief discussion of mono- and poly-syllabicity and how these are related to
morhemes in our target languages, we establish a set of criteria regarding the identification of
word-forms to be used throughout the remaining analysis. Each morphological sub-division is
then analyzed with the following results:
-
Affixation – highly productive.
-
Reduplication – highly productive.
-
Base Modification – non-productive.
-
Conversion – non-productive.
-
Base shortening – rarely productive.
-
Blends and acronyms – marginally productive.
-
Unique morphs – rarely productive.
-
Suppletion – non-productive.
Thus, after examining the productivity of morphological phenomena in Chinese and Vietnamese
according to the nine standard categories proposed by Bauer (2003), we have found evidence that our
two languages demonstrate varying degrees of productivity in six out of the nine categories. Three of
these, were rated highly productive, our top designation of productivity. While we find word-building
evident to a lesser degree in the three categories of base shortening, blends and unique morphs, there
seems to be no evidence of any bona fide morphological activity in the areas of base modification,
conversion and suppletion. Overall, we conclude that Chinese and Vietnamese, though not
heavyweights in the morphology arena, are indeed far from playing a mere bantam role. Their
performance in the realm of affixation and compounding alone should serve as proof of the
morphological dexterity of these languages.
Main References:
Bauer, Laurie. 2003. Introducing Linguistic Morphology. Washington, D.C.: Georgetown University Press.
Hoang, Van Hanh. 1994. Tu-dien tu lay tieng Viet [Dictionary of Vietnames reduplications]. Hanoi: Giao-duc.
Lü, Shuxiang. 1981. Yuwen Chang Tan [Talking about language]. Beijing: San Lian Shudian.
Maspero, Henri. 1912. Étude sur la phonétique historique de la langue Annamite [Studies in the phonetic
history of the Annamite language]. Bulletin de la do l’Ecole Francaise d’Etreme-Orient. 12.1.1–127.
Nguyen, Dang Liem. 1969. Vietnamese Grammar: A combined tagmemic and transformational approach. Canberra: The Australian National University.
Nguyen, Dinh Hoa. 1997. Tieng Viet khong son phan [Vietnamese without veneer]. London Oriental
and African Language Library. Amsterdam: John Benjamins Publishing Compnay.
Packard, Jerome L. 2000. The Morphology of Chinese: Alinguistic and cognitive approach. Cambridge:
Cambridge University Press.
Phi, Thuyet Hinh. 1977. Thu tim hieu tu lay song-tiet dang X-AP + X-Y [Understanding the di-syllabic
reduplications of the X-AP + X-Y type]. Ngon-Ngu [Language] 34 (December). 42-50.
Prager, David. 2002. Common Chinese and early Chinese morphology.
Journal of the American
Oriental Society
, Vol. 122, Issue 4.
San, Duanmu. Wordhood in Chinese. http://www-personal.umich.edu/~duanmu/wordhood98.pdf
Thompson, Laurence C. 1965. A Vietnamese Grammar. Seattle: University of Washington
Utz Maas (Osnabrück)To be mono(syllaba) - or not to be mono
In Preparation
Ian Maddieson (Albuquerque)Monosyllables and syllabic complexity
Languages vary widely in what proportion of their lexicon consists of monosyllables — some are reported to have no monosyllabic words (e.g. Pintupi), while others have beenanalyzed as having only monosyllables (e.g. Wa). Most languages fall somewhere inbetween these extremes.
A reasonable expectation might be that the proportion of a vocabulary that ismonosyllabic is correlated with the richness of syllabic possibilities in the languageconcerned. That is, having short words is facilitated by having larger inventories ofsegmental and suprasegmental contrasts and richer combinatorial possibilities (Fenk-Oczlon & Fenk 2008). For example, RP English has (by some analyses) 19 vowel nucleiand 24 consonants, and allows up to 3 consonants in onset and up to 4 in coda, as in stream and sixths. A large number of potential monosyllables can be created from these resources,despite numerous limitations on permitted combinations. On the other hand, the Tacananlanguage Cavineña has just 4 vowels and 20 consonants and allows no codas and no onsetclusters (Guillaume 2008). Thus many fewer potential monosyllables exist. But does thegreater potential result in greater actual numbers of monosyllables?
The objective of this paper is to investigate if the generality of the hypothesizedrelationship can be demonstrated across a sizeable sample of diverse languages. Inparticular, it aims to examine whether there are independent correlations between inventorysize and proportion of monosyllables, and between phonotactic freedom and proportion ofmonosyllables. In order to do this a number of difficult methodological issues must first beconfronted.
Issues concerning what form of a lexeme to consider are particularly problematical.Dictionaries typically select a particular form to cite. For verbs, it is traditional to cite thefirst person present singular in Latin, but the infinitive in French. Thus, amo and aimer, both disyllabic. But if the infinitive had been chosen for Latin the item would be trisyllabicamare, and if the first person form had been chosen for French it would be a monosyllable. If the stem rather than any form with an inflection had been chosen (as in Young et al's1992 Navajo dictionary) both Latin and French would show monosyllabic forms.
In view of the biases introduced by such choices it might seem better to examine textualmaterials, rather than dictionary entries. This would sample the range of syllabic forms that any lexeme takes, such as the monosyllabic French forms aime, aimes, aiment (all /ɛm/), as well as disyllabic aimez, aimerai, etc, and longer forms. However, the hypothesis underinvestigation concerns lexical resources, not word frequency, so counting the proportion ofmonosyllabic words in running text does not address the question. A closer approach wouldbe to calculate the number of distinct monosyllabic word forms as a proportion of all wordforms. But a text has a biased selection of lexical items depending on its topics, whichintroduces a different problem unless the texts are matched.
Another problem concerns the scale of the vocabulary available for analysis. Languagessuch as English or French are used in a tremendous range of social and geographic settings,and have enormous lexicographical resources which record (and help keep alive) all kindsof specialized technical terms as well as archaic and nonce words. Comparing such materialwith vocabularies of the many languages where only a few hundred or a few thousandwords are available risks making the comparison one between vocabulary sizes.
For these practical reasons initial explorations of the hypothesis are under way on bothlexical entry forms and on word forms in short matched wordlists and texts. Matched smallvocabularies, such as those often used for preliminary diagnosis of linguistic relatedness,are available for many languages. Samples from sources like the Intercontinental Dictionary Series (http://lingweb.eva.mpg.de/ids/ ) and the Austronesian Basic Vocabulary Database (http://language.psy.auckland.ac.nz/austronesian/ ) are analyzed for languages whoseinventory size and phonotactic constraints are known. Word shapes in text are compared forlanguages represented in the 'Illustrations of the IPA' and other sources that use thestandard 'North Wind and the Sun' passage for text exemplification. Proportions ofmonosyllables vary greatly in the texts — from 3% (Tamil) to 80% (Thai) with a mean ofaround a quarter. Preliminary results suggest that richness of consonant inventory or ofbasic vowel quality inventory do not predict a higher proportion of monosyllables, but thetotal number of vowel contrasts and phonotactic freedom may do so.
References:
Guillaume, A. 2008. A Grammar of Cavineña. Mouton de Gruyter, Berlin.Fenk-Oczlon, G. & A. Fenk. 2008. Complexity trade-offs between the subsystems of language. In M. Miestamo, K. Sinnemäki & F. Karlsson (eds) Language Complexity:Typology, Contact, Change. John Benjamins, Amsterdam: 43-65.
Young, R., W. Morgan, & S. Midgette. (1992). An Analytical Lexicon of Navajo. Albuquerque, University of New Mexico Press.
Alexis Michaud (CNRS, Paris)Monosyllabicization: patterns of evolution in Asian languages
Asian languages reveal a continuum from quasi-disyllables to highly eroded monosyllables. These variegated states are now understood to be different stages along a common evolutionary path. A general overview is proposed, tracing the diachronic developments involved: monosyllabicization, which results in complex monosyllables that are especially rich in consonants; and processes of consonantal depletion, which lead to the development of phonation-type registers and tones. The synthetic presentation of these major ‘panchronic’ phenomena is followed by a discussion of evolutions observed at advanced stages of segmental depletion.
Andrey Mikhalev (Pyatigorsk, Russia)On the project of a new Dictionary of English Rimes
Among the various kinds of dictionaries in the lexicographic tradition, there is one which was initiated in Medieval Europe, the Dictionary of Rimes. Its practical use was bounded by poetic purposes, which is why the first composers of rime lists were troubadours. Since that time Rime Dictionaries have been made and published in France, in Spain, in Germany, in England, in Russia and in many other countries for other languages. So, there would be a reasonable question: what is the need of another one?
The point is that careful attention to the use of rimes in poetry reveals a certain semantic integrity of words with the same final part. This is perhaps quite natural in the case of grammatical rimes and other riming suffixes accompanying root morphemes. But in other cases, the rime may be the final part of a root morpheme itself, which is obvious in monosyllabic words (
b-ad, s-ad, m-ad,
etc.) and even in bisyllabic ones with the rimes like -utter, -atter, -itter that can not pretend to be suffixes.
Our own study of the semantics of English rimes which has been based on 249 rimes with different degrees of productivity (from 2 to 49 lexemes), has revealed an obvious trend towards the structuring of meanings.
So, the first and chief difference of the “Phonosemantic Dictionary of English Rimes” from traditional ones is in an explanatory hypersemantic approach. Each article representing a rime gives the distribution of riming words by semantic fields in accordance to revealed hypersemes.
Another distinctive feature of the “Dictionary” is its synoptic two-part composition. Our research has shown that the discovered semantic fields recur repeatedly with various rimes, which is motivated by the same phono-semantic principles. In consequence, a list of a rather restricted number of fields (hypersemes) embracing all the registered rimes has been established. That is why we found it reasonable to present the first part of the Dictionary in a semasiological aspect, i.e. (1) to group all English rimes in an alphabetic order; (2) to exhibit all riming words for each rime; and (3) to integrate all riming words in semantic fields, abstracted from their meanings.
The second part of the “Dictionary” represents an onomasiological approach. It contains the list of all revealed semantic fields and an index of the rimes conveying each given field. In addition, it would be useful to note the productive quotient of each rime in the realization of a given field. For instance, the semantic field ROUND (including its semantic derivates CONTAINER, COVER, SPACIOUS, BIG, ROLL, BEND) occurs in the following rimes (in total 37): -ulk (in 3 riming words out of 3, i.e. 100%); -undle (2/2 = 100%); -oop (12/14 = 86%); -oon (10/12 = 83%); -ull (15/19 = 79%), etc.
We would suggest that such a synoptic approach has both practical and theoretical importance. In the analysis of poetic composition and in general studies in poetics, this Dictionary could help to expose the deeper semantics of pieces of poetry, which emerges early in the hypersemes of rimes. As for linguistic theory, the study of rime semantics and its results shed light on the iconic trends in the lexico-semantic organization of English in particular and human languages in general.
Matthew Moreland (University of Reading, UK)The Status of the Post-Initial Jod in British English: Evidence from Wordlikeness Judgements of Monosyllabic Nonwords
In Modern RP English, the distribution of the post-initial jod (i.e. the jod in /(C)Cj-/ sequences) is heavily skewed in terms of the vowels which can follow it – more than 95% of all word-initial /Cj-/ onsets precede one of /uː/, /ʊǝ/ or /ʊ/ (according to the Reading University CEPD-BNC Calculator, RCB). This is notably different to the distribution of word-initial /Cw-/ sequences, for which the top three following vowels account for just over 54% of such occurrences. Phonotactic evidence similar to this and evidence from studies of word games and aphasia have been used to suggest that post-consonantal jod in American English is not an onset consonant, but part of the nucleus and potentially an onglide element to a diphthongal /juː/ vowel (e.g. Davis & Hammond, 1995; Barlow, 2001; Buchwald, 2005). Although the history of English pronunciation appears to predict some of these findings (see Cooley, 1978), such an analysis would make /juː/ the sole example of a rising diphthong in English. The present study turns to native speaker perceptions of wordlikeness and wellformedness and considers whether such judgements support an onset or nucleus assignment of the post-initial jod.
Building on prior research showing relationships between phonotactic probabilities and wordlikeness judgements (e.g. Coleman & Pierrehumbert, 1997), lexical and sublexical statistics for various monosyllabic /CCVC/ nonword stimuli are obtained by creating several versions of the RCB, a phonotactic probability and neighbourhood density calculator combining a 60,000-lemma subset of the Cambridge English Pronouncing Dictionary (Jones et al., 2006) with per-million frequency counts from the British National Corpus (from Leech, Rayson & Wilson, nd). Each version of the RCB assumes different onset/rime assignments for different types of jod (initial and post-initial, those before /uː/ and those before other vowels, plus considerations of monophonemic versus biphonemic interpretations of diphthong vowels).
The wordlikeness measures, including the common heptary scale and proportional binary 'yes/no' wellformedness judgements, are compared with a new reaction-time-adjusted binary setup. To test this method, the 124 post-initial jod stimuli (30 /CjuːC/, 94 with a different vowel) are supplemented by 25 /bCɪk/ and /pCɪk/ items (in addition to /pjɪk/ and /bjɪk/) and 15 stimuli used by prior studies. All stimuli are monosyllabic in order to avoid questions of stress and syllable boundaries, and presented in the frame ‘The next item is [X]’.
These pre-repetition judgements are supplemented by nonword repetitions and post-repetition judgements for each stimulus. The participants were 24 monolingual British English speaking adults, with no known hearing/speaking/learning difficulties, recruited as either schooled in or long-term residents of the borough of Wokingham (approximately 65 km west of London).
References:
Barlow, J. (2001). Individual differences in the production of initial consonant sequences in Pig Latin. Lingua, 111, 667-696.
Buchwald, A. (2005). Representing sound structure: evidence from aphasia. In:Proceedings of the 24th West Coast Conference on Formal Linguistics (J. Alderete, C. Han and A. Kochetov, eds.). Somerville, MA: Cascadilla Proceedings Project. 79-87.
Coleman, J.S. and Pierrehumbert, J. (1997). Stochastic phonological grammars and acceptability. In:Computational phonology. Third meeting of the ACL special interest group in computational phonology. Somerset, NJ: Association for Computational Linguistics. 49-56.
Cooley, M. (1978). Phonological constraints and sound changes. Glossa, 12(2), 125-136.
Davis, S. and Hammond, M. (1995). On the status of on-glides in American English. Phonology, 12, 159-182.
Jones, D., Roach, P., Hartman, J. and Setter, J. (2006). Cambridge English pronouncing dictionary (17th edn.). Cambridge: Cambridge University Press.
Leech, G., Rayson, P. and Wilson, A. (nd). Companion website for: Word frequencies in written and spoken English: based on the British National Corpus. [WWW Resource]. Available from: http://www.comp.lancs.ac.uk/ucrel/bncfreq/ [accessed 19/11/08].
Toshihiro Oda (Tokyo)The Application of Monosyllabic Word-finals to Coda Maximization:
Phonetic Preferences and the Irrelevancy of Sonority
Despite the crosslinguistically attested Stressed Syllable Law, which is defined as dimoraic rhymes in stressed syllables, Present-Day English (PDE) has more than two rhymes in stressed environments as a result of more than one coda consonant (e.g. AmE gui[lɾ].i, BrE ce[nʔ].er). Wells’ works refer to the syllabification as stress attraction and Hammond (1999) as Max-Coda. The very relevant research contains ambisyllabification and resyllabification. Due to the coda maximization, even stressed rhymes with four morae appear (AmE pai[nɾ].er). This paper points out the phonetic preferences of maximized consonants in the coda. Incidentally, whether word-medial consonants affiliate to unstressed syllable-initial or preceding stressed coda-final gives rise to articulatory differences (e.g. the duration of preceding sonorants) and the divergence of allophonic distributions.
Since late-1990s, phonetic motivations constitute a topic frequently addressed in the literature: markedness constraints (Kirchner 2001, Hall 2004 and others), Dispersion Theory (Flemming 2002), the mechanism (Hayes 1999), Licensing by Cue (Steriade 1997), phonological changes (Howell and Wicka 2007 and Blevins 2008) and allophonic increase (Oda 2008). Phonological motivations, which were actively discussed in particular in 1980s, involve some sonority-based principles and the OCP and features and generalizations play a decisive role in the conditioning. By contrast, phonetic roots are reflected by speakers’ knowledge regarding physical activity: movement and posture inside mouth, opposite or smooth articulations, the way of air flow, duration and others.
The forms in AmE [lɾ, nɾ] (e.g. guilty, enter) represent a case of coda maximizations. These clusters are phonetically easier since both of them have the tongue contact with alveolar ridge before the articulation of the tap. The movement has preference to the sequence other nasal plus the tap. The tap following ‘r’-coloring also presents a better one owing to the articulation from neutral position to the quick return to the original position. The sequence [nɾ] is more common than the one [lɾ], as demonstrated in the words such as center, winter and international. The tongue contact (alveolar) of the nasal is close to that of the tap in comparison with that of the lateral. This means that the phonetic preference and the occurrence of the clusters correlate with each other.
The second case is shown to be the clusters (/sp, st, sk/, /mp, ŋk/)) where an unaspirated voiceless stop occupies the syllable-final second coda. Note the syllabic affiliation of stressed codas, instead of unstressed onsets. The former are pronounced as unaspirated stops and the latter as, only slightly in general terms, aspirated ones. Whereas PDE has foot-initial strong pronunciations irrespective of stress (cf. Kiparsky 1979, Jensen 2000), the majority of aspirated stops in unstressed syllables occur in foot-initial positions (e.g. [tʰ]oday, we are going to … ). The environment of coda maximizations is equivalent to non-foot-initial. Thus, the second consonants of the clusters at issue suit for the unaspirated ones, those in coda-final. (Further examples will be added to the ones in the above two paragraphs.)
At first glance, PDE coda maximization seems to result from the sonority of vowels. PDE has the strong tendency that vowels with larger sonority value are stressed. Then, owing to the larger sonority distance with marginal consonants, coda maximization may become possible. However, this is not the case. AmE tapping occurs irrespective of sorts of vowels and the case of low vowels is less common than that of each of mid and high peripheral vowels. The reason for considering so is basic and frequent words which contain the allophone. German is slightly similar in the sense of stressed vowels with larger sonority, but it definitely has dimoraic rhymes in stressed syllables, which are not caused by the sonority of vowels. The reason of PDE coda maximization is therefore not the sonority of vowels, but the phonetic preference of the coda clusters.
References:
Blevins, J. (2008), Phonetic Explanation without Compromise, Diachronica 25, 1–19.
Flemming, E. (1995), Auditory Representations in Phonology, Doctoral Dissertation, UCLA. [published by Routledge, 2002.]
Hall, T. A. (2004), On the Nongemination of /r/ in West Germanic Twenty-one Years Later, Folia Linguistica Historica 25, 211–234.
Hammond, M. (1999), The Phonology of English, Oxford: Oxford University Press.
Hayes, B. (1999), Phonetically Driven Phonology: The Role of Optimality Theory and Inductive Grounding, Formalism and Functionalism, Volume 1: General Papers, eds. by M. Darnell, E. Moravsick, M. Noonan, F. Newmeyer and K. Wheatly, 243–285, Amsterdam and Philadelphia: John Benjamins.
Howell, R. B. and K. S. Wicka (2007), A Phonetic Account of Anglian Smoothing, Folia Linguistica Historica 28, 187–214.
Jensen, J. T. (2000), Against Ambisyllabicity, Phonology 17, 187–235.
Kiparsky, P. (1979), Metrical Structure Assignment is Cyclic, Linguistic Inquiry 10, 421–441.
Kirchner, R. (1998) An Effort-Based Approach to Consonant Lenition, Doctoral Dissertation, UCLA. [published by Routledge, 2001.]
Oda, T. (2008), Phonetically Based Allophones and the Sharp Increase of Syllabic Consonants in the History of English: Against the Phonological Motivations, presented at the 15th International Conference on English Historical Linguistics
Steriade, D. (1997) Phonetics in Phonology: The Case of Laryngeal Neutralization, downloadable at the website: http://www.linguistics.ucla.edu/people/steriade/papers/phoneticsinphonology.pdf
Paula Orzechowska (Adam Mickiewicz University, Poznań)Effects of morphology on the syllable structure – English right edge phonotactics
Goal
The objective of this paper is to discuss the phonology of English monosyllables. We test the hypothesis that phonological attributes and preferability of a consonant cluster vary depending on its morphological composition. Following Dressler – Dziubalska-Kołaczyk's (2006) proposal to distinguish between phonotactic and morphonotactic clusters, we provide a salient distinction between coda clusters which occur within a single morpheme (i.e. in the intramorphemic context: /ld/ in cold) and clusters which emerge across morphemic boundaries in concatenative morphology (i.e. in the intermorphemic context: /ld/ in call+ed). The phonological properties of phonotactic and morphonotactic clusters is determined on the basis of auditory distances between adjacent sounds measured in terms of three parameters: sonority, place of articulation and voicing.
Data
In this study we collected 164 coda clusters occurring in monosyllabic English words. Representative entries were extracted from the New Kosciuszko Foundation Dictionary(NKFD) (Fisiak 2003). Traditional dictionary data provides lemmata (e.g., nominative singular nouns and infinitive verbs) and therefore fails to account for coda clusters emerging in the morphological context. The NKFD, however, apart from 74 intramorphemic coda clusters (e.g., /lb/ in bulb, /rl/ in pearl, /kst/ in text) also contains 90 intermorphemic coda types found in plural noun and past verb forms (e.g., /rz/ in bar+s, /pt/ in shape+d, /lfth/ in twelf+th).
Methodology
Since sonority has been shown to be too simplistic in the description of consonantal strings in phonotactically complex languages such as English (Maddieson 2008), we used the criterion of Net Auditory Distance (NAD) (Dziubalska-Kołaczyk 2008) to determine degrees of cluster preferability. NAD of a cluster is determined by specifying the manner of articulation, place of articulation and voice characteristics of sounds neighbouring on one another. With the help of NAD, we propose a 4-degree continuum of cluster preferability (i.e. preferred CC > dispreferred CC > preferred CCC > dispreferred CCC) established separately for intramorphemic and intermorphemic clusters.
Results
The results of the study confirm the hypothesis that there is a correlation between the degree of cluster preferability and clusters' morphological composition. We demonstrate that coda (i.e. word final) clusters which emerge intermorphemically are generally less preferred than their intramorphemic counterparts. We observe a tendency (i.e. 59%) for intermorphemic clusters to be dispreferred (e.g., /ðd/ in bathe+d, /ʧt/ in pitch+ed, /rmd/ in arm+ed). The reverse is true for intramorphemic doubles and triples, among which more than a half (also 59%) is preferred (e.g., /ls/ in pulse, /rf/ in scarf, /rsk/ in torsk). A closer examination of the two groups of clusters lends further support to the claim.
Of all phonologically motivated sequences, preferred -CC are the most frequent and constitute 42% of all intramorphemic types. As the preferability of intramorphemic clusters decreases from the most preferred (marked 1.) to the least preferred (marked 4.), the number of types representing each preferability degree decreases significantly as well (1.=42% > 2.=32% > 3.=18% > 4.=8%). The tendency is much weaker for intermorphemic clusters, which are most frequently represented by dispreferred doubles (37%), and for which the number of types representing preferability degrees 2., 3. and 4. decreases gradually (2.=37% > 3.=33% > 4.=22%). The class of the most preferred clusters, i.e. -CC marked 1. contains 7 types, which translates into only 8% of all intermorphemic clusters. From the aforementioned facts it transpires that morphology not only has an impact on the phonological shape of clusters but also contributes to their universal dispreferability.
References:
Dressler, Wolfgang Ulrich – Katarzyna Dziubalska-Kołaczyk. 2006. “Proposing morphonotactics”, Wiener Linguistische Gazette 73: 1–19.
Dziubalska-Kołaczyk. 2008. NP extension. (A paper presented at the 39th Poznań Linguistic Meeting, 11–14 September 2008.)
Fisiak, Jacek (ed.). 2003. Nowy Słownik Fundacji Kościuszkowskiej [The New Kosciuszko Foundation Dictionary]. New York: The Kosciuszko Foundation.
Maddieson, Ian. 2008. “Syllable structure”, in: Martin Haspelmath – Matthew S. Dryer – David Gil –Bernard Comrie (eds), The world atlas of language structures online. Oxford: Oxford University Press, chapter 12 (date of access 03.07.2009.)
Pravin Pralayankar (Chennai, India)Monosyllabic Adverbs in Sanskrit
The primary aim of the paper is to look at the semantic and syntactic nature of monosyllabic adverbs in Vedic literature, mainly principal Upanishads. Due to capability of changing its position in a sentence, it becomes difficult to capture the syntactic nature of adverbs even for the fixed word order languages but this becomes more challenging for the language like Sanskrit where word order is relatively free.
In Sanskrit old grammatical tradition ( Pre-Paaniniyan), we have four types of part of speech; naam (noun), aakhyaat (verb), upasarga (preverb/preposition) and nipaat (particle). But Paanini allows only two categories; subanta (noun) and tinanta (verb) inhis Astaadhyaayi. So, according to Paanini, there is nothing called adverb on its own in Sanskrit. But when we look at the definition of adverb, we find that adverbs are discussed as avyaya (a category of subanta) in Astadhyaayi, 1.1.37-41. Without going into details of these sutras at this point, I would like to say that the semantic based concept of adverbs in modern grammar and linguistics can be easily incorporated within the framework of the grammar of Panini which is more phonologically and morphologically influenced. In this paper I’ll make an attempt to show how both the concepts can be merged together.
While explaining the sutras stated in 1.1.37-41 of Panini, we get a set of examples mentioned as avyaya in Sidhaantakaumudi, Kashika and LaghuSidhaantakaumudi. In these set we find twenty nine monosyllabic avyaya like ca ‘and’, chet ‘If’, kil ‘certainly’ vaa ‘option’, ha ‘popular’ etc. A initial look on these words shows that there meaning is not fixed. For example, in example (1a) ha corresponds to ‘famous’ while in (1b) it has definite meaning.
(1a)
atha
then
ha
famous
enam
this
kausalyah
inhabitant of kosala
aashvalaayanah
aashvalaayana
paprachcha
ask.pst
‘Then Ashvalaayana, inhabitant of Kosala asked to this famous (saint).’
(1b)
aadityo
sun
ha
certainly
vai
only
baahya-praaNah
internal-life
‘Certainly, only sun is internal life.’
As far as syntax is concerned, in sentence (1a) ha is acting as an modifier of pronoun enam resulting as an adjective but in sentence (1b) it is an adverb.
So this particular work will have twofold importance. Firstly, to see how these monosyllabic avyaya of Sanskrit can be merged within the framework of adverb and secondly, to illustrate the semantic and syntactic nature of some of the monosyllabic adverbs present in principal Upanishad literature.
References:
[1] Cardona, G., Indian Grammarians on Adverb, Issuies in Linguistics; Parer in honour of Henry and Renee Kahane, ed, Braj B, Kacharu et al., Urbana, 1978, 85-98
[2] Cinque, G., Adverbs and Functional Heads: A cross Linguistics Perspective, New York, Oxford University Press.
[3] Gombrich, R., He cooks Softly: Adverbs in Sanskrit Grammar, Bulletin of the School of Oriental and African Studies London 42:22, 244-256, 1979.
[4] Kiparsky, P., Panini’s razor, Symposium on Sanskrit and Computational Linguistics, Paris, Oct. 29-31, 2007
[5] Shastri, Dharaananda. Laghusidhaantakaumudi, 2002, MLBD, Delhi
[6] Speijer, J.S. Sanskrit Syntax, 1980, MLBD, Delhi
[7] Pralayankar, P. (Ms) Sanskrit Adverbs: From Tradition to Modern Linguistics, Malayalam Grammatical Theories: Tradition to the Present, ,Kerala University, Trivandrum, 23-25 Mrach 2009.
Bhahavi Savaranan (Stony Brook University)Lexically stratified monosyllables
This paper looks at monosyllable types in Dravidian language Tamil in different strata of the lexicon: the native (core) and borrowed (peripheral) vocabulary. While monosyllables are very common in native Tamil, a richer variety is seen in the borrowed vocabulary. Ito and Mester (1995) argue that elements in the lexical core (native) satisfy all lexical constraints, while elements at the periphery (borrowings) really only meet the truly fundamental constraints on syllable structure. This results in the differences between native and foreign output. Contrary to that claim, monosyllables in the peripheral strata in Tamil violate syllable structure constraints, revealing that at least in Tamil, a subset of faithfulness constraints is ranked over fundamental syllable structure constraints.
The minimality requirement in Tamil requires that monosyllables (and all prosodic words) contain two moras. Given the bimoraic minimality, the possible types of monosyllables are: CVC as in (1), CV: as in (2), and CV:C as in (3).
(1) [kəl] ‘stone’
(2) [pʊː] ‘flower’
(3) [pɑːl] ‘milk’
The coda in the CVC and CV:C monosyllables has to be a sonorant (obstruents are not permitted word-finally). There is a fourth possibility for a bimoraic monosyllable: CVCC. However, the CVCC monosyllable is unattested in native Tamil as consonant clusters are impermissible word-finally. A CVCC input is syllabified as CVCCV, as shown in (4).
(4) [kəmb] ‘stick’ (unpronouncible) à [kəmbɨ].
The resulting form is unfaithful to its input because it is constrained by SyllStruc (which includes constraints against complex codas, complex onsets, etc.) that outranks all other constraints, including Faith, being faithful to the input. This is shown in (5):
(5) SyllStruc > Faith
With borrowed monosyllables we see all the monosyllable types found in the native Tamil as well as those not attested therein, the latter given below:
(6) CVC (ending in an obstruent) [bəs] ‘bus’
(7) CVCC (ending in a consonant cluster) [pQnt] ‘pant’
(8) CV:C (ending in an obstruent) [vɑɪf] ‘wife’
(9) CV:CC (ending in a consonant cluster) [kɑɪnd] ‘kind’
This must be seen as a consequence of reranking of constraints in the peripheral strata, as remaining faithful to the foreign input is more sacrosanct than obeying the native syllable structure format; this reranking is given in (10).
(10) Faith > SyllStruc
Syllables are the foundational skeleton on which higher prosodic units are built, and constraints on syllable structure are often inviolable. However, (relatively recent) English borrowings into Tamil do exactly that and do not seem to meet even the bare minimum, fundamental requirements that syllable structure constraints be obeyed. The ranking in (10) reflects this.
References:
Caldwell, R. 1977. A Comparative Grammar of the Dravidian or South Indian Family of Languages. New Delhi: Asian Educational Services.
Ito, J. & Armin Mester. 1995. The Core-Periphery Structure of the Lexicon and Constraints on Reranking. In: In Jill Beckman et al., eds., Papers in Optimality Theory, UMOP 18, 181–209. U. of Massachusetts, Amherst: GLSA.
Connie K. So (MARCS, University of Western Sydney, Australia)Cross-language perception and categorization of monosyllabic foreign tones: Effects of phonological and phonetic properties of native language
Studies have shown that properties of one' native language exert significant impact on perception of foreign sound segments (Polka, 1991; Werker & Tees, 1984), yet our knowledge about how native language constrains the perception of foreign tones is very limited (So, 2006). Additionally, the question as to how listeners perceive foreign tones is still waiting for an answer.
This study examined how native language could affect (a) listeners' sensitivities of foreign tones on monosyllables, and (b) the categorization of foreign tones in terms of their native words with different prosodic categories. Two experiments were conducted: one was tonal identification and the other one was tonal categorization. Two typologically different languages (Fox, 2000; Yip, 2002) – Hong Kong Cantonese (a syllable-timed tone language) and Japanese (a mora-timed pitch-accented language) – were used as the tested languages, and the target language for the stimuli was Mandarin. All native speakers of the two languages were naïve to Mandarin at the time of the study. Their perceptual sensitivity scores and categorization patterns were collected for analysis.
The results indicated that both phonological and phonetic properties of native languages affected the perception of Mandarin tones, and that foreign tones were preferentially categorized in terms of the existing native words of the tested languages, which shared similar tone features. Their implications will be discussed.
References:
Fox, A. (2000). Prosodic features and prosodic structure: The phonology of suprasegmentals. New York: Oxford University Press.
Polka, L. (1991). Cross-language speech perception in adults: Phonemic, phonetic, and acoustic contributions. The Journal of Acoustical Society of America, 89(6), 2961–2977.
So, C. K. (2006). Effects of L1 prosodic background and AV training on learning Mandarin tones by speakers of Cantonese, Japanese, and English. Unpublished PhD Thesis, Simon Fraser University.
Werker, J. F., & Tees, R. C. (1984). Phonemic and phonetic factors in adult cross-language speech perception. The Journal of Acoustical Society of America, 75, 1866–1878.
Yip, M. (2002). Tone. Cambridge: Cambridge University Press.
Petra Steiner (University of Erfurt)Relations with Monosyllables: A View from Quantitative Linguistics
The methodological approach of Quantitative Linguistics (QL) is based on the functional-analytic model of explanation, as formulated by Hempel (1959) and adapted for explaining linguistic phenomena by Altmann (1981) and Köhler (1986: 28ff, 1990: 13ff, 2005: 764f). According to this model, linguistic phenomena and relations are parts within a self-organizing and self-regulating system. This system is a complex entity of requirements, linguistic properties, and relations between them. System requirements are being postulated on the basis of general assumption on language, and often they are linked to external instances (e.g. human memory). Prominent requirements are efficiency needs, also called the principle of least effort (Zipf 1949: 67). Such requirements can be met on different linguistic levels (supra-sentence structures, sentence, clause, phrase, word-form, syllable, phoneme, suprasegmental features etc.) and by different means, so-called functional equivalents. The relative frequencies of functional equivalents differ over genres, languages and time. For instance, the genitive can be expressed by preposed or postposed nominal phrases (as in English of the tenth century) or by prepositional phrases. From such frequencies and the relations between functional equivalents, testable hypotheses on linguistic phenomena can be derived and explained. Examples of corroborated hypotheses which were deduced from such explanatory models are Zipf’s laws (Prün 2005), Menzerath-Altmann’s law (Altmann & Schwibbe 1989) and diversification processes (Rothe 1991, Steiner & Prün 2007).
Within Quantitative Linguistics, hypotheses on the linguistic unit syllable and its quantitative properties length, frequency and redundancy/entropy have been already investigated and partially corroborated. Especially Menzerath-Altmann’s law on the length of syllable as function of word length and other related connections is well confirmed (Fenk & Fenk-Oczlon 1993, Fenk-Oczlon & Fenk 1999). Also, extensive investigations on word length distributions do exist, showing functions of the form Px = g(x)Px-1 where x is the word length (in syllables) and g(x) the variable proportion between adjacent classes (Wimmer & Altmann 1996). However, an extended model for syllables, their relations with other linguistic units and their properties in a system-theoretical model has not yet been developed. Models in synergetic linguistics usually do not comprise syllable (length) (cf. Köhler 1986, 2005b) and if a level between word form or lexeme and the phoneme is included, it is mostly the morph or morpheme (cf. Krott 1996, Steiner 1995).
The length of syllables is influenced by the system requirement of transmission security. This need creates redundancy, which can be met by increasing the length of linguistic units (see Köhler 2005b: 766) by four different functional equivalents of phonological, morphological, syntactical and lexical means, which are complementary to each other. These linguistic means lead to competing effects on the lengths of different linguistic units, which are inversely connected by the Menzerath-Altmann’s law (see Figure 1).
Figure 1: The effect of redundancy on the length of linguistic units
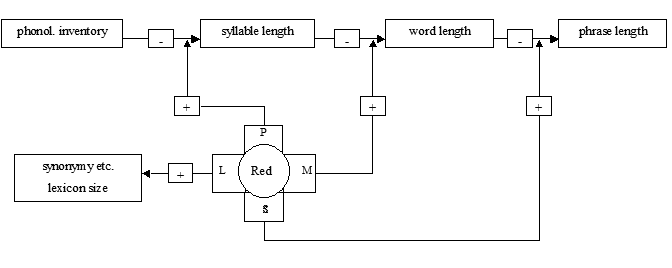
Redundancy, which is the complement of entropy, is minimized if all events have the same probability. This, however, is the case for word-segmentation in monosyllabic languages (or languages with word-forms of the same syllabic size). What is maximized by this linguistic phenomenon, is the segmentability of units. However, the uniformity of the segments has to be compensated by a greater redundancy on the level of segment length. Therefore the (average) length of segments must increase in relation to their entropy. The more uniform the shapes of linguistic units on one level, the more information must be invested on others. This general assumption leads to more specific hypotheses on the relations of (mono-)syllables with other linguistic entities.
References:
Altmann, Gabriel (1981). Zur Funktionalanalyse in der Linguistik. Esser, Jürgen & Axel Hübler, ed. Forms and Functions: papers in General, English, and Applied Linguistics presented to Vilém Fried on the occasion of his sixty-fifth birthday. Tübingen: Narr, 1981. (Tübinger Beiträge zur Linguistik 149). 25–32.
Altmann, Gabriel & Michael H. Schwibbe (1989). Das Menzerathsche Gesetz in informationsverarbeitenden Systemen. Hildesheim/Zürich/New York: Olms.
Fenk, August & Gertraud Fenk-Oczlon (1993). Menzerath’s Law and the Constant Flow of Linguistic Information. Köhler, Reinhard & Burghard B. Rieger, ed. Contributions to Quantitative Linguistics. Proceedings of the First International Conference on Quantitatitve Linguistics, QUALICO, Trier, 1991. Dordrecht/Boston/London: Kluwer. 11–31.
Fenk-Oczlon, Gertraud & August Fenk (1999). Cognition, quantitative linguistics, and systemic typology. Linguistic Typology 3. 151–177.
Hempel, Carl G. (1959). The Logic of Functional Analysis. Gross, Llewellyn, ed. Symposium on Sociological Theory. New York: Harper and Row.
Köhler, Reinhard (1986). Zur linguistischen Synergetik: Struktur und Dynamik der Lexik. Bochum: Brockmeyer. (Quantitative Linguistics 31).
Köhler, Reinhard (1990). Linguistische Analyseebenen. Hierarchisierung und Erklärung im Modell der sprachlichen Selbstregulation. Hřebíček, Ludek, ed. Glottometrika 11. Bochum: Brockmeyer. 1–18. (Quantitative linguistics 42).
Köhler, Reinhard (2005a). Gegenstand und Arbeitsweise der Quantitativen Linguistik. Köhler, Reinhard, Gabriel Altmann & Rajmund G. Piotrowski, ed. Quantitative Linguistik/Quantitative Linguistics: Ein internationales Handbuch/An international handbook. Berlin/New York: de Gruyter. (Handbücher zur Sprach- und Kommunikationswissenschaft /Handbooks of Linguistics and Communicative Science 27). 1–16.
Köhler, Reinhard (2005b). Synergetic linguistics. Köhler, Reinhard, Gabriel Altmann & Rajmund G. Piotrowski, ed. Quantitative Linguistik/Quantitative Linguistics: Ein internationales Handbuch/An international handbook. Berlin/New York: de Gruyter. (Handbücher zur Sprach- und Kommunikationswissenschaft /Handbooks of Linguistics and Communicative Science 27). 760–774.
Krott, Andrea (1996). Some remarks on the relation between word length and morpheme length. Journal of Quantitative Linguistics 3.1. 29–37.
Prün, Claudia (2005). Das Werk von G. K. Zipf. Köhler, Reinhard, Gabriel Altmann & Rajmund G. Piotrowski, ed. Quantitative Linguistik/Quantitative Linguistics: Ein internationales Handbuch/An international handbook. Berlin/New York: de Gruyter. 142-152. (Handbücher zur Sprach- und Kommunikationswissenschaft/Handbooks of Linguistics and Communicative Science 27).
Rothe, Ursula. Diversification processes in grammar. An Introduction. Rothe, Ursula, ed. Diversification Processes in Language: Grammar. Hagen: Rottmann, 1991. 3–32.
Steiner, Petra (1995). Effects of Polylexy on Compounding. Journal of Quantitative Linguistics 2.2. 133–140.
Steiner, Petra & Claudia Prün (2007). The effects of diversification and unification on the inflectional paradigms of German nouns. Grzybek, Peter & Reinhard Köhler, ed. Exact methods in the study of language and text: dedicated to Professor Gabriel Altmann on the occasion of his 75th birthday. Berlin: de Gruyter. 623–631.
Wimmer, Gejza & Gabriel Altmann (1996). The Theory of Word Length: Some Results and Generalizations. Schmidt, Peter, ed. Glottometrika 15: Issues in General Linguistic Theory and The Theory of Word Length. Trier: WVT Wissenschaftlicher Verlag Trier. 112–133.
Zipf, George Kingsley. Human behavior and the principle of least effort. An introduction to human ecology. Cambridge/Mass.: Addison-Wesley, 1949. Reprinted in New York: Hafner, 1972. [page numbers refer to the latter].
Shanti Ulfsbjorninn (SOAS, University of London)Formalising ‘Monosyllabicity’ to Capture Phonological Incorporation
To call some languages ‘monosyllabic’ presupposes the existence of what we might call a ‘syllable’ along with its array of problems:
Emmanuel Nikiema?: The only thing we can be sure about talking about
syllables is that everyone almost in this room would agree that CV is a syllable. Whether
CVC is a syllable, CCV is a syllable, or two or three, we don't know.
Harry van der Hulst: No, but there is no agreement that even CV is a syllable.
CUNY Phonology Forum on the syllable 2008
One way to resolve this dispute is to examine the minimal word in Austro-Asiatic and Maremmano Italian (Ulfsbjorninn 2007), Altaic (Charette 2008), Germanic (Pochtrager 2006), Dinka (Ulfsbjorninn forth.), Sino-Tibetan (Goh 1997). In these languages we find that a major category lexeme may never be smaller than CV: or CVC, hence analogising the minimal word in many ‘polysyllabic’ languages with the minimal/maximal word in ‘monosyllabic’ languages. This link between ‘polysyllabic’ and ‘monosyllabic’ languages suggests that, whatever we call them, there is a general tendency for words to be made up of a certain shape, ‘building block’, or CVX (this comparison between Chinese-like and English-like words is seen in Duanmu (2008)).
The major empirical advantage of seeing ‘monosyllabic’ words as building blocks rather than syllables is that a syllable, as constituent, is devoid of any particular structure. However, we see very real spacial restrictions on what can be adjoined to a monosyllabic word without resorting to compounding or the creation of phrases. In many languages when a clitic adjoins to a word its shape becomes restricted to V, CV, CN etc… (for Vietnamese see Pham 2003). Evidence for this comes from the following languages.
Maremmano Italian words that violate the minimal-size constraint cannibalise articles by incorporating them into the word while (trochaically) assigning main stress to the usually non-tonic clitic:
/’ka:za/ ‘house’ + /la/ ‘the’ → /la ‘ka:za/ but /dzo/ ‘zoo’ + lo ‘the’ → /’lodz:o/
Lhasa Tibetan is a predominantly ‘monosyllabic’ language although some words seem to be historical combinations of the minimal-word plus a CV i.e. /bu:/ ‘boy’ + /mo/ ‘fem.’ → /bu:=mo/ ‘girl’. Crucially, certain endings are incorporated into the word and these replace the final ‘CV’ of the ‘polysyllabic’ words: /bu=mo/ → /bu=CV/ (Chonjore and Abinanti 2003).
Simplifying somewhat, Cantonese uses a modal suffix /dak/ which may be added to ‘monosyllabic’ loans: /pin/ ‘print’ but not with ‘polysyllabic’ loans (Tang 2002).
Mon-Khmer and Kammu both add a ‘minor’ syllable to a ‘major’ syllable (CV:, CVC) to create their lexical items. In both cases, the shape of the minor syllable is heavily restricted to CV or CN (Bickel et al. 2006).
Together, these representative facts seem to indicate that the structure for the ‘monosyllabic’ words in ‘monosyllabic’ languages clearly exceedes the standard representation of the Khanean ‘syllable’ although it is not unrestricted. Facts from a variety of languages back up Lowenstamm (1999) and Charette (2008)’s claims for cliticisation sites in addition to the word.
We will conclude that ‘monosyllabic’ words in ‘monosyllabic’ languages have the following structure (which is, the combination of Goh (1997) and Duanmu (2008)’s CVX and Lowenstamm and Charette’s respective initial and final cliticisation sites represented in onsets and nuclei:
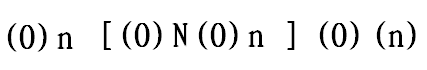
This structure, as we will demonstrate, captures our prior-stated facts surrounding incorporation into ‘monosyllabic’ words, while hinting at a diachronic path for the building of smaller words into larger words i.e. by fossilising the incorporated material in the cliticisation sites flanking the main word.
References:
Bickel. B., Hildenbrandt, K. and, R. Schiering. (2006). Are there Phonological Principles Determining Phonological Word-Size?. (ms.) University of Leipzig and University of Manchester.
Cairns, C. (2008). http://www.cunyphonologyforum.net/Fridisc.php
Charette, M. (2008). The Vital Role of the Trochaic Foot in Explaining Turkish Word Endings. In Lingua, 118.1:46-65.
Chonjore, T. and A. Abinanti, (2003). Colloquial Tibetan. Library of Tibetan Works and Archives.
Duanmu. San. (2008). A CVX theory of Syllable Structure. Presented at: CUNY Phonology Forum on the Syllable, New York.
Goh, Y. S. (2007). The Segmental Phonology of Beijing Mandarin. Crane.
Lowenstamm, J. (1999). At the Beginning of the Word. In: Phonologika 1996: Syllables !?, The Hague: Thesus 153-166.
Pham, A. H. (2003). Tone in Vietnamese: a new analysis. In: Outstanding Dissertations in Linguistics, Routledge.
Pochtrager, M. (2006). The Structure of Length. PhD Dissertation, University of Vienna.
Tang, S. W. (2002). Focus and DAK in Cantonese. In: Journal of Chinese Linguistics. 30.2:266-309.
Ulfsbjorninn, S. (2007). The Structural Identity of the Phonological Word in Vietnamese. Presented at: the Phonological word in South and South East Asian Languages, University of Leipzig.
Ulfsbjorninn, S. (forth.). The Processing of Compounds: Evidence from Aphasia. In: Iberia.
Sabine Zerbian (Johannesburg, South Africa)The phonology of monosyllabic stems in Sotho-Tswana (Southern Bantu)
It is well-known that Bantu languages have minimality requirements both on word size and stem size (Myers 1987, Downing 1999, 2001 a.o.). Words are always minimally bisyllabic, stems need to be bisyllabic in certain constructions only (Downing 2001). The current paper summarizes the special segmental phonology of monosyllabic stems in the Sotho-Tswana languages. It furthermore reports new experimental data on the special suprasegmental behavior of monosyllabic stems in these languages.
In the imperative, the only verb form that surfaces as the bare stem in the singular, a stabilizer vowel is inserted stem-initially in Tswana, as shown in (1a). Monosyllabic noun stems are regularly complemented by a class prefix when they surface as words. However, the prefix of class 9 is a syllabic nasal (N) which induces fortition on stem-initial consonants. It is dropped with polysyllabic stems and only surfaces with monosyllabic stems to ensure bisyllabicity at the word-level, (1b).
(1) Tswana (Cole, 1955)

With respect to minimality at stem-level, in the Participial Present Tense the verb stem (as opposed to the Word) needs to be minimally bisyllabic which leads to the insertion of a stabilizing vowel before a monosyllabic verb stem, (2a). In the construction of adjectives, the complement to the obligatory demonstrative prefix needs to be bisyllabic with the effect of retaining the class 9 prefix with monosyllabic adjective stems, (2b).
(2) Tswana (Cole, 1955)

Monosyllabic stems also show peculiar behavior with respect to the application of tone rules. In the nominal domain, the noun class prefix of monosyllabic noun stems cannot be raised by a preceding word-final high tone, contrary to noun class prefixes of polysyllabic stems (3).

Furthermore, our acoustic study has shown that in the verbal domain, the high tone on the stem-initial syllable of a monosyllabic verb stem is produced with a considerable steeper rise than the high tone of a polysyllabic verb, which reaches the peak only in the following syllable in Northern Sotho, (4a) (and does not spread onto the following word as in Tswana in (3)). Furthermore, whereas a high-toned object infix induces a peak shift to the subsequent syllable in polysyllabic verb stems, this peak shift is cancelled out in monosyllabic verb stems, (4b). The talk presents the acoustic data of four speakers of Northern Sotho to corroborate these observations.

References:
Cole, D.T. (1955). Introduction to Tswana Grammar. Cape Town: Longman.
Downing, L.J. (1999). Prosodic Stem ≠ Prosodic Word in Bantu. In: T.A. Hall & U. Kleinhenz (eds.) Studies on the Phonological Word. Amsterdam: John Benjamins. Pp. 73-98.
Downing, L.J. (2001). Ungeneralizable minimality in Ndebele. Studies in African Linguistics 30: 33-58.
Myers, S.P. (1987). Tone and the Structure of Words in Shona. PhD dissertation, University of Massachusetts, Amherst.