Determining just that information that is to be expressed, or realized, in a generated text is a complex issue that depends on a variety of factors, including at least what the intended audience wants to know and the degree of detail that the intended audience requires. These factors also constrain considerably the functional tasks that a natural language generation system needs to address. We can characterize these tasks in terms of three general areas of variation.
These three sources of constraint provide then additional intermediate `inputs' to the generation process. They allow a first step in the mapping from the information that is to be used, or is available, for generation and offer a basis for making a variety of more fine-grained decisions on a motivated and appropriate basis. In some cases it may be possible for aspects of this information to be deduced from other aspects--e.g., particular classes of texts may only support particular kinds of communicative goals and be available only to particular classes of hearers/readers--in other cases the information must be provided in some way prior to generation. Their interrelationship is summarized graphically in Figure 6. All allow a particular range of flexibility to be achieved in the content-determination decision process; this has consequences for the precise information and structures that are passed on to subsequent stages of processing.
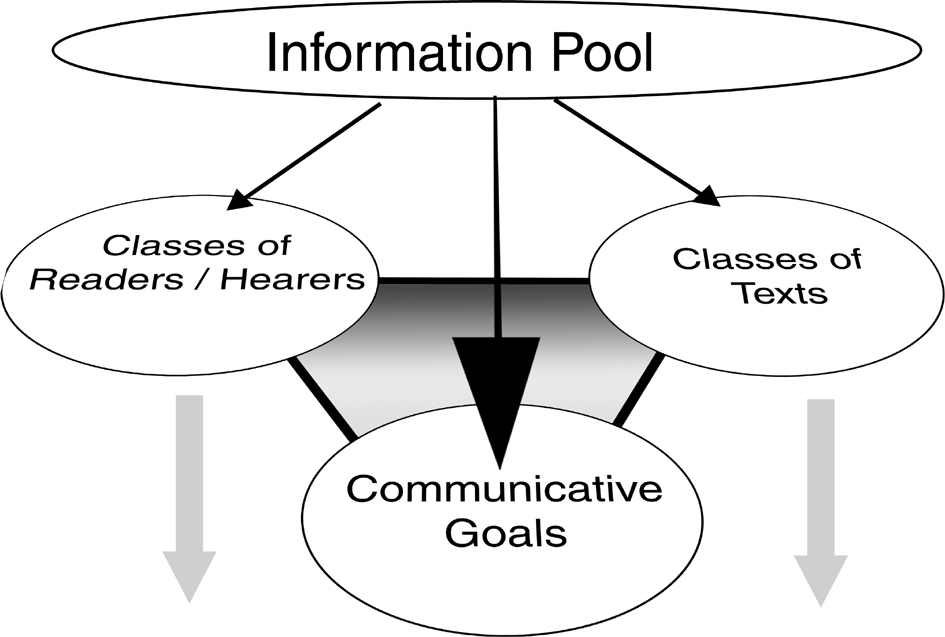 |
Three
basic sources of constraint in the mapping process between information
and text |
Representing distinct classes of users is generally done by means of user modelling (cf., e.g., [Wahlster and Kobsa: 1989,Jameson: 1989,Rich: 1989,McCoy: 1988,Paris: 1993,Peter and Rösner: 1994,Jameson: 2001]). Here the generation system maintains a model of the hearer including what the hearer is expected to know, what has been communicated previously in the text, what the hearer generally likes to know, etc. This information can then be used to guide or restrict content selection. One complication is the question of how an accurate user model can be gained--here it has been argued that an interactive system can use its interactions to improve its model of the user and that, in any case, fixing a user model with any great accuracy is undesirable or even impossible (cf. [Sparck Jones: 1991,Moore and Paris: 1992]). Another important direction here is that of producing differing linguistic behavior dependent on the cognitive constraints under which an addressee is laboring at the time that the produced text is to be interpreted--e.g., whether the addressee is at that moment grappling with other complex tasks or not; this area is known as resource-adaptive user modeling [Jameson, Schäfer, Weis, Berthold and Weyrath: 1999] and considers variation such as that exhibited between an instruction such as ``turn into the small street at the third house on the left'' and one such as ``left now!'' depending on the speed being travelled at. When a system undertakes no user modelling, then the particular audience classes and needs become part of the specification of the NLG system's functionality and is not then available subsequently for motivating variation in the texts produced.
During the generation of any text--spoken or written--the current state of development of the text has to be carefully tracked. This includes information concerning what entities have been introduced, from what perspective, and what communicative goals are currently pending, which have been achieved, and so on. This information is necessary so that aspects of textuality such as anaphoric (pronominal) reference and newsworthiness can be appropriately controlled. NLG systems producing spoken language output generally talk here of a `dialog history' which is built and maintained by a `dialog manager' (e.g., [Horacek: 1990,Luperfoy, Nijholt and van Zenten: 1996]). An appropriate dialog manager helps considerably also in the interpretation of a speaker's utterances to a conversational system by constraining the likely communicative moves being undertaken at any particular point in the discourse. NLG systems producing written language generally talk of a `discourse model', which would minimally include focus information concerning what entities are currently within the `focus of attention' of the speaker and which therefore can be referred to with appropriate pronominal forms [McKeown: 1985,McCoy and Cheng: 1991,Henschel, Cheng and Poesio: 2000,Kruijff-Korbayová, Kruijff and Bateman: in press].
Representing and using knowledge of text types is usually done by explicitly providing an account of macrostructure (cf., e.g., [van Dijk: 1980,Martin: 1992]). This relies on the fact that particular types of texts have particular regularly reoccuring structures that should be adhered to during generation. This clearly offers a useful organizing framework for NLG. Significant for content selection is that particular parts of the text macro structure require the expression of particular kinds of information--for example, in certain classes of artist biography it is normal that name, dates of birth and death be followed by a text stage concerning education, which is in turn followed by details of career, followed finally by the most well-known works of art created. Although often `explainable', such text structures are essentially arbitrary and have to be specified as the way of writing particular kinds of texts in the language in question. They therefore provide one direct means of specifying what the hearer expects to be told in particular circumstances. Generic structures of this kind were introduced into text generation as text schemas by McKeown [McKeown: 1985] and have played an important role in structuring texts in NLG ever since.
Both user modelling and macro text structure definitions provide partial answers to the question of what information is relevant for the text being generated. Relevance can only be assessed relative to an information need: user modelling defines information needs in terms of the hearer, text structure defines information needs in terms of the norms of a language culture. A further source of relevance is oriented to the speaker: for example, if the text is to get some point across, possibly presenting arguments or even examples (cf. [Mittal: 1993]), then content material must be selected appropriately in order to provide support. Speaker-oriented content decisions are usually considered in NLG work in terms of communicative goals and `discourse planning' (cf. [Appelt: 1985b,Hovy: 1988b,Moore and Paris: 1988]). The selection of some content is then the `solution' to the planning problem raised by the need to satisfy some set of communicative goals; this is a particularly popular approach when generating dialog contributions. Also, since goal-oriented planning provides a very general metaphor, it can readily be adopted for the other aspects of content selection: thus both user models and text structures can give rise to speaker goals where what the intended hearer wants, needs, or expects to know is treated as a communicative goal of the NLG system. Treating all system decisions as fulfillments of communicative goals can lead, however, to theoretical underdifferentiation.
Although introduced here under content selection, both text macro organization and discourse planning are usually discussed under the topic of text structuring, to which we return below. This is another instance of the difficulty in defining `modules' in the generation process. Almost all kinds of linguistic structuring--such as text structuring and sentence structuring by grammar--commit equally to selections of `content'. For example, the fact that the `sex' slot of the information shown in Figure 5 has to contribute to the selected content (supporting the semantic type female in the example SPL) is strongly motivated by the demands of the grammar of English; indeed, most languages of the world require grammatically that information concerning natural gender be available, otherwise pronoun selection (`he' vs. `she') would not be possible. But which particular set of information is necessary depends on the individual grammars of particular languages: some languages might require that the generation process know whether one or more than one object is being discussed in order to select singular or plural nominal groups and agreeing verbs (`The dog runs' vs. `The dogs run'), other languages might not (e.g., Japanese where a single sentence is compatible with both the English sentences); other languages might require that the generation process knows not only whether there is one or more object, but additionally whether there are exactly two objects or not (e.g., languages such as Arabic with the distinction: singular, dual, and plural), or whether the objects in question are long and thin or wide and flat (e.g., languages such as Japanese or those of the Bantu family where such distinctions are necessary when producing phrases that, for example, count such objects). Languages might also require specific discriminations in the types of objects refered to that were not foreseen in the initial modelling (as in famous translation problems such as the distinction drawn in Spanish between live fish and fish for eating). There can even be substantial differences in the kinds of information required: whereas the example input shown above is mostly sufficient for an acceptable English text, a corresponding Japanese text would ideally also require information concerning the relative social statuses of the hearer and speaker--otherwise the correct morphological forms of verbs cannot be determined.
These considerations lead to a complex of further related problems for NLG. The fact that all `modes' of description of a text (e.g., grammatical, lexical, morphological, text-structural) can bring constraints to bear on the information expressed--loosely, the `content'--presents difficult architectural questions. Any system that first decides what is to be said and then subsequently goes about organizing (`packaging') that content in order that it be expressed may fail to have selected sufficient information to guarantee successful generation. Complete content selection can only be achieved as a separate step if the content selector `knows' the requirements of the grammar (and all other modes of text organization). But this weakens the modularity of the NLG process where, it is generally hoped, individual modules (e.g., `content selection') would not need to consider information maintained in other modules (e.g., grammar). In fact, it seems that whatever input is provided on the basis of application knowledge or domain modelling, the particularities of a language may result in further information being necessary. Conversely, some information that is provided may turn out to be unusable by the grammar of some language. A hard match between input and output as traditionally required in a computational component is thus rendered problematic.
This leads to an even higher probability of significant mismatch between the information that is available in some concrete application domain for a generator and the information that that generator needs in order to generate text in any specific language. Semantic modelling too often follows `common sense' and exactly which aspects of real-world knowledge are picked out by common sense depends on the patterns established by the native language(s) of those who are doing the modelling. Attempts to provide a more reliable basis for modelling form a very active area of research and development termed `ontological engineering' (cf. [Patil, Fikes, Patel-Schneider, McKay, Finin, Gruber and Neches: 1992,Guarino and Poli: 1994]): standardizations have been proposed in particular areas, but general standards are still a matter of (sometimes heated) debate. For NLG, this has been likened to the alchemists' problem of turning lead into gold: no applications provide sufficiently detailed information for `optimal' NLG and so some enrichment of that information is always necessary. Almost any example of real generation considered offers examples of this. In our example texts and illustrative knowledge structure above, consider the treatment of temporal expressions. The information present in the knowledge representation has to be `enriched' to form a temporal representation suitable for supporting expression in English. This is complicated by distinctions necessary (for English) such as those illustrated in: `in 1933', `on 3rd. June 1933', `in June 1933', etc. The NLG system needs to know more than a simple absolute reference to time: the linguistic ontology needs to be expanded to differentiate at the very least between years, months, and days. More subtle is the `enrichment' necessary in the example to obtain an event with specified temporal and spatial locations from the bare slots for place and date of birth; this is a reoccuring problem when shifting from the object-centered representations still prevalent in application models to the event-centered representations more suited to NLG. The mappings required here can be quite complex.
Considered multilingually, it may not even be theoretically possible for an `adequate' representation to exist equally for all languages; this is the much studied `interlingua' problem of machine translation (p [])119]HutchinsSomers92cf. which is equally relevant for NLG, particularly for multilingual generation (cf., e.g., [Polguère: 1991]). The interlingua experience strongly suggests that waiting for an ideal representation will not be a successful strategy. It is necessary to adopt techniques that ease the transition from the information that is actually available to the information entailed by any text. This problem is an essential part of NLG, requiring as principled a solution as possible. Methods currently in use include `default' selections made on the basis of user models and text types. This permits defaults to be non-arbitrary and sufficiently flexible as not to compromise the generic utility of the NLG component. `Hardwiring' defaults is similar to hardwiring sublanguages and raises the cost of re-use significantly; note that such hardwiring can also occur when an adopted linguistic account does not make the distinctions that are necessary for the flexibility desired--here hardwiring is imposed by the theory.