The simplest approach to the second task is to set up mapping tables from the domain categories to the linguistic resources of the generator (p [])91]Meteer92-bookcf.; this guarantees the modularity of the application information and, providing the level of linguistic representation adopted is sufficiently abstract, maintains the possibility of flexible realization. However, a domain-specific encoding of how the application domain requires its information to appear is still problematic. It requires detailed knowledge on the part of the system builder both of how the generator controls its output forms and the kinds of information that the application domain contains. A more general solution to the interfacing problem is desirable. This is particularly difficult when the task is one of interfacing a domain-independent, reusable, general NLG system with a particular application domain: application-internal information needs to be related to strategies for its expression.
If the initial representation of the application can itself be readily manipulated, then an alternative approach is to progressively replace configurations of elements of the domain representation with other configurations that are nearer (in structure or content) the surface structure to be generated. One variation here is the application of semantic transformations described by Horacek [Horacek: 1990]. Such approaches can coincide with the assumption that there is no principled difference between non-linguistic, application domain information and semantic information of a linguistic nature. Another variation is the progressive replacement of application terms by lexical material in approaches based on the Meaning-Text-Model (e.g., [Iordanskaja, Kittredge and Polguère: 1991]). This approach also works with the linguistic notion of strata used above, beginning with more abstract configurations and progressively replacing them with linguistically more concrete material.
Another technique that has found wide application is to reduce the mappings possible between domain and NLG-terms to just the relation of logical subsumption. This is facilitated when any particular instances of facts, states of affairs, situations, etc. that occur in the application can be classified in terms of a hierarchy of general objects and relations that behave systematically with respect to their possible linguistic realizations. Such a hierarchy is provided, for example, by the Upper Model [Bateman, Kasper, Moore and Whitney: 1990,Bateman: 1990] first defined for use within the Penman text generation system [Mann: 1983b,Matthiessen and Bateman: 1991]; current versions of this hierarchy include around 150 concepts. The classification of domain concepts in terms of the Upper Model then allows domain terms to inherit their possibilities for linguistic expression. In principle this does not interfere with domain-internal or application-specific organizations and requires expertise neither in the lexicogrammar nor in the mapping between Upper Model and lexicogrammar. An application need only concern itself with the `meaning' of its own knowledge, and not with details of linguistic form; the classification therefore functions as an interface between domain knowledge and the NLG system. Responsibility for the correct realization of semantic types remains solely with the NLG system employing an Upper Model. When the classification has been established for a given application, application concepts can be used freely in input specifications since their possiblities for linguistic realization are known: this is how the domain types used in the example inputs shown in Figures 1 and 2 (e.g., bearing, city, study, etc.) are interpreted. Figure 7 depicts graphically the relationship between a general Upper Model and particular application knowledge: the NLG system knows how Upper Model concepts such as `person', `directed process' and so on may be expressed in the languages it covers--the former concept as an animate nominal phrase, the latter as, for example, a transitive clause construction--and the domain concepts such as `Albers', `emmigrate' then inherit these possibilities.
This kind of interfacing technique supports two significant functionalities:
Many systems now make use of a level of semantic organization similar to the Upper Model; the most up-to-date description of an implemented Upper Model is that of the Generalized Upper Model [Bateman, Henschel and Rinaldi: 1995], although the theory that it is based upon has since been developed further [Halliday and Matthiessen: 1999].
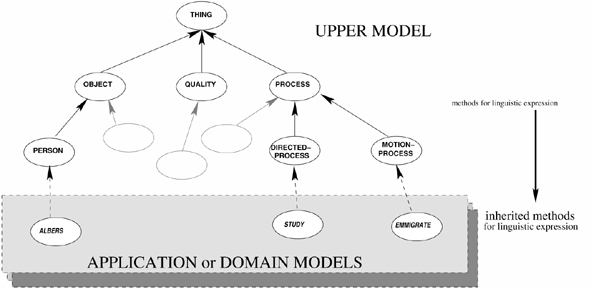 |
Relating
the information of an application with an Upper Model by subsumption in
order to inherit methods for linguistic expression |
The use of an Upper Model level of representation is compatible with an interpretation of domain knowledge as semantic information since the subsumption relationship serves to bind them together. This can lead to problems (cf. the discussions in, e.g., [Teich and Bateman: 1994,Stede and Grote: 1995]); an Upper Model is by definition a linguistic semantics and a domain model need not be. Conflating the two may be a convenient engineering decision in particular contexts--i.e., with particular restricted degrees of variability in linguistic realization required--but can be no more than this. In the most general case, the relation between domain terms and semantic terms requires a mapping which is itself subject to text planning constraints, text type, and the particular language involved. More flexible accounts that nevertheless allow principled constraint are needed.