We have now sketched a framework for the `what' of generation: i.e., those tasks of generation that are intrinsically part of the problem. Consistent choices need to be made ideationally, interpersonally, and textually in order to construct sequences of semantic specifications that are supportive of textuality and which provide sufficient information for their expression in grammatical units. Regardless of how any particular generation system is designed or implemented, these tasks are inescapable: not explicitly dealing with some set of the issues restricts the flexibility of the resulting system in particular predictable (and sometimes therefore justifiable) ways. Turning to the `how' of generation, and some of the concrete techniques that have been proposed for representing linguistic information and the algorithms for its processing, the position is less clear. Different theoretical viewpoints or patterns of practice group the above tasks and their linguistic consequences differently; some accounts may conflate information from different strata, may not distinguish metafunctions, may separate out information contained in the lexicogrammar along metafunctional lines (e.g., semantics/pragmatics) or by specificity (e.g., lexicon/grammar). Moreover, particularly in a larger system, it is unlikely that all aspects of that system reflect a homogeneous instantiation of some theory in implementation: well worked out parts might accurately reflect aspects of an underlying theoretical account; others reflect the necessity of having a working system. Discussions of systems need therefore to be more careful than they often are concerning which aspects are theoretically motivated and which are more ad hoc engineering. This can give rise to sometimes puzzling differences in `modules' and, consequently, in areas of debate, between accounts.
The `modules' that will be described here correspond to the abstract tasks of the generation process described above--particularly, lexicogrammar (realizations of more abstract modes of description in terms of less abstract modes of description involving grammatical configurations and their accompanying lexical material), and text `planners' (goal-oriented construction techniques for sequences of loosely sentence-sized semantic specifications). We also detail the most common interfacing problems between such modules: those between discourse semantics and lexicogrammar, and between application and NLG systems. For orientation in the discussion, an overview of a complete generation architecture is shown graphically in Figure 4. Application information is accessed in the top left-hand corner, and a sequence of grammatical specifications resulting in an unfolding text appears in the lower right. Interaction between components is shown bidirectionally, even though many architectures choose not to support this possibility. Many differences between approaches reside in the flexibility they assign to the inter-level mappings: individual leaves of the text structure may, for example, map onto single semantic specifications or sequences of semantic specifications; similarly, individual semantic specifications may map onto sequences of lexicogrammatical specifications. Simpler relationships are often adopted however.
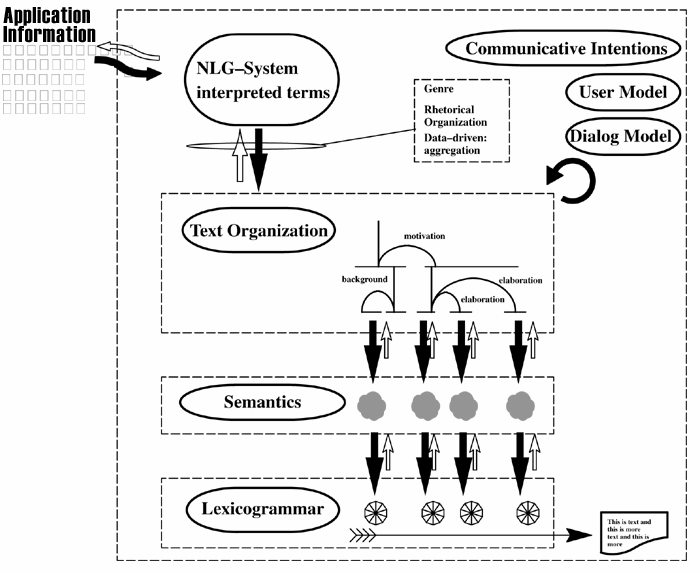 |
An abstract
generation system and tasks (modules and mappings) in overview |
Recently researchers in NLG have begun attempting to standardize natural language generation architectures. Due to the extreme variability of purposes that a generation system might be asked to undertake, it is usual to restrict the range of systems examined to particular kinds. One of the most thorough attempts to date is that of the Reference Architecture for Generation project `RAGS' [Cahill, Doran, Evans, Kibble, Mellish, Paiva, Reape, Scott and Tipper: 2000]. In this project, the focus was placed on the set of `applied' natural language generation systems, defined by particular criteria set by the RAGS project itself. The RAGS-model also proposes a collection of tasks within a generation system as done here, although these tasks draw not on a specification of the linguistic problems faced when creating text, but rather on modules that have commonly been assumed in applied NLG systems--in particular modules arising from Reiter's [Reiter: 1994] proposals for a `consensus' pipeline (see below) architecture for NLG systems. This is nevertheless useful, since it is also can be used to classify a significant proportion of the NLG literature and there have now been attempts to relate a number of generation systems to the RAGS-model [AIS: 1999]. These early attempts to apply the RAGs architecture have shown that the functional tasks identified in RAGs are often distributed broadly over different components in any particular generation system [Cahill, Doran, Evans, Kibble, Mellish, Paiva, Reape, Scott and Tipper: 2000]. This can be taken as a sign either that these tasks really are so distributed or that the definitions of the tasks have less theoretical/practical integrity than hoped. The truth lies probably in some combination of these extremes. For the purposes of the present review, we will here therefore continue to orientate our account to the tasks raised by the linguistic system itself.