Kapitel 4: Syntax
Vorbemerkung
Der Terminus Syntax sowie eine Anzahl verwandter Termini wie syntaktisch, Syntagma,
syntagmatisch sind vom griechischen Wort συνταξις [syntaksis] 'Ordnung', 'Anordnung'
abgeleitet, das aus den Elementen συν- [syn-] 'zusammen' und ταγ-/τακ- [–tag–/–tak–]
‘anordnen, aufstellen’ besteht. Informell können wir sagen, daß Syntax
sich damit beschäftigt, auf welche Weise Wörter zu Sätzen zusammengefügt werden.
Die Syntax ist eines der am weitesten entwickelten Teilgebiete der modernen Linguistik
und kann in einem allgemeinen Einführungskurs nur in Umrissen behandelt werden.
Ziel dabei ist es, die wichtigsten grundlegenden und allgemein anerkannten Begriffe
und Methoden zu vermitteln. Die Behandlung von Details muß weiterführenden speziellen
Syntaxveranstaltungen vorbehalten bleiben.
Anknüpfend an die Ausführungen im Kapitel Semiotik werden wir Wörter als
Zeichen auffassen, die einen Ausdruck mit einem Inhalt assoziieren, wobei der Ausdruck
den Inhalt symbolisiert, z.B. sym(boy, ‘boy’). Konventionellerweise
wird die Ausdrucksseite durch Kursivschrift (boy) und die Inhaltsseite durch
einfache Anführungszeichen (‘boy’) wiedergegeben. Bei einer Betrachtung
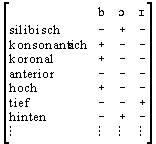
als lautsprachliches Zeichen kann die Ausdrucksseite auch in phonemischer oder phonetischer
Umschrift dargestellt werden (/bɔɪ/ bzw. [bɔɪ], wobei diese selbst nur eine konventionelle
Abkürzung für eine komplexe Informationsstruktur ist (beispielsweise eine Matrix
phonetischer Merkmale wie nebenstehend). Die Notation ‘boy’ für die
Inhaltsseite ist nicht mehr als ein Etikett für eine möglicherweise komplexe und
mehrdeutige Inhaltsstruktur, die wir noch nicht kennen. Beispielsweise ist versucht
worden Begriffe in Bedeutungskomponenten zu zerlegen, im vorliegenden Falle etwa
[nonadult, male, human].
Sätze haben selbst Zeichencharakter, d.h. sie assoziieren einen Ausdruck und einen
Inhalt. Für einen einfachen Satz wie
(4.1.) Boys admire girls
gilt also die Symbolisierungsrelation sym(boys admire girls, ‘boys
admire girls’). Andererseits ist (4.1.) aus Elementarzeichen zusammengesetzt,
die jeweils für sich einen Ausdruck und einen Inhalt haben.
(4.2.)
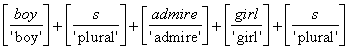
Damit stellt sich die Frage, wie einerseits die Ausdrucksstruktur boys admire girls
aus den Ausdrucksstrukturen der Elementarzeichen entsteht, und wie sich andererseits
die Inhaltsstruktur ‘boys admire girls’ aus den Inhalten der Einzelzeichen
ableiten läßt. In beiden Fällen ist das Ganze mehr als die Summe seiner Teile.
Im Falle der Ausdrucksstruktur ist das Grundprinzip die lineare Verkettung. Wie
sich im weiteren Verlauf dieses Kapitels zeigen wird, geht es jedoch um mehr als
die bloße lineare Aneinanderreihung von Zeichenformen, die Verknüpfung erfolgt vielmehr
in einzelnen hierarchischen Stufen. Auf der untersten Stufe haben wir die Verknüpfung
von Elementarzeichen (Morphemen) zu Wörtern, z.B. boy + s → boys, girl + s →
girls. Die Behandlung dieser Prozesse ist vorrangige Aufgabe des Teilgebietes
der Morphologie (s. Kapitel 5). Wir werden im weiteren zunächst von Wörtern als
Grundzeichen ausgehen:
(4.3.)
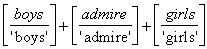
Bei der Bildung des Gesamtausdruckes boys admire girls ist zunächst davon
auszugehen, daß admire und girls zum Ausdruck admire girls
verknüpft werden: admire girls =admire×girls (× ist ein
Verknüpfungszeichen, wofür oft auch das Pluszeichen '+' oder einfach das
Leerzeichen verwendet wird). Dies ergibt wiederum verkettet mir boys den
Gesamtausdruck: boys admire girls = boys×(admire×girls). Dieser
hierarchische Aufbau ist sowohl für die lautliche Realisierung bedeutsam (Satzbetonung,
Intonation) als auch für die Satzbedeutung.
Im Gegensatz zu den Elementarzeichen sind die Inhalte von Sätzen nicht arbiträr
(im Sinne von de Saussure), sondern durch die Regeln der Grammatik motiviert. Dabei
wird vom Prinzip der Kompositionalität der Bedeutung komplexer Ausdrücke ausgegangen.
Definition 4.1. Kompositionalität
Das Prinzip der Kompositonalität der Bedeutung komplexer Ausdrücke besagt, daß die
Bedeutung solcher Ausdrücke sich aus den Bedeutungen der einzelnen Elementarzeichen
in Abhängigkeit von der syntaktischen Struktur zusammensetzt.
Wir werden auf die Frage, wie die Inhalte der komplexen Ausdrücke von Sätzen aus
den jeweiligen Inhalten der Elementarzeichen, aus denen sie aufgebaut sind, abgeleitet
werden können, später zurückkommen. Für den Augenblick betrachten wir nur das kombinatorische
Potential von Wortformen.
Konstituenz und Dependenz
Zwei zentrale Begriffe der Syntaxtheorie sind Konstituenz und Dependenz. Dabei handelt
es sich um zwei wesentliche Grundprinzipien der Satzorganisation, die sich gegenseitig
bedingen bzw. als sich gegenseitig ergänzend zu betrachten sind. Das Prinzip der
Konstituenz beruht auf der Teil-Ganzes-Beziehung zwischen Satzbestandteilen (z.B.
"ein Satz besteht aus Subjekt und Prädikat"). Das Prinzip der Dependenz
oder Abhängigkeit beruht auf der Tatsache, daß zwischen Ausdrücken im Satz mehr
oder weniger enge Beziehungen bestehen, so z.B. zwischen Attribut und Bezugswort
(ein schlauer Fuchs) oder zwischen dem Verb und seinen Ergänzungen (Er begegnete
einem Zombie). Diese beiden Relationen sollen in den folgenden Abschnitten
genauer betrachtet werden.
Allgemeine Grundbegriffe
Zunächst werden wir einige allgemeine Begriffe wie Sprache, Satz, Äußerung Grammatik,
Grammatikalität etc. besprechen.
Im folgenden wollen wir den Terminus Sprache für die Zwecke der Syntax in einem
sehr speziellen und eingeschränkten Sinn verwenden:
Definition 4.2. Sprache
Eine Sprache ist eine Menge von Sätzen, von denen jeder aus einer endlichen Menge
von Elementen aufgebaut ist, L = {S1, S2,S3, …}
Damit ist z.B. die englische Sprache die Menge der englischen Sätze, die deutsche
Sprache die Menge der deutschen Sätze. Es läßt sich begründen, daß die Anzahl der
Sätze in einer natürlichen Sprache wie Englisch oder Deutsch unendlich ist, auch
wenn ein Angehöriger der betreffenden Sprachgemeinschaft im Laufe seines Lebens
nur eine endliche Menge von Sätzen äußern kann. Jeder Satz Si=sym(Ai,
Ij) ist ein komplexes Zeichen, d.h. die Assoziation eines (komplexen)
Ausdrucks Ai und eines (komplexen) Inhaltes Ij
, wobei der Ausdruck den Inhalt symbolisiert.
Sätze müssen von Äußerungen unterschieden werden. Satz und Äußerung stehen im Verhältnis
von Typ (type) und Exemplar (token) zueinander. In den folgenden beiden
Texten kommt der Ausdruck Suddenly the door opened zweimal vor:
|
(4.4.)
|
(a) It was quiet and dark. Suddenly the door opened.
|
|
|
(b) He was almost napping. Suddenly the door opened.
|
Es handelt sich um zwei verschiedene Äusserungen, d.h. zwei verschiedene konkrete
Realisierungen des gleichen Satzes.
Definition 4.3. Äußerung
Eine Äusserung ist ein Satzexemplar, d.h. eine konkrete Realisierung eines Satzes
in einem Kommunikationszusammenhang.
Definition 4.4. Vokabular
Die Menge der Elemente, aus der die Sätze einer Sprache aufgebaut sind, ist das
Vokabular dieser Sprache.
Im gegenwärtigen Diskussionszusammenhang fassen wir die Elemente des Vokabulars
als Wörter in einem intuitiven Sinn auf. Das Vokabular der englischen Sprache ist
die Menge der englischen Wörter.
Definition 4.5. Kette
Jede lineare Anordnung von Elementen des Vokabulars bildet eine Kette von Elementen.
Wenn das Vokabular aus Wörtern besteht, was wir für den Augenblick annehmen wollen,
sind Ketten aus Wörtern zusammengesetzt. Mit dem Vokabular der englischen Wörter
sind die folgenden mögliche Wortketten über diesem Vokabular:
|
(4.5.)
|
(a) everyone knows that James Bond is invincible
|
|
|
(b) * knows is that James invincible everyone Bond
|
Definition 4.6. Teilkette
Eine Kette ki, die Teil einer anderen Kette k j ist, ist eine
Teilkette dieser Kette.
So ist very difficult eine Teilkette von a very difficult question,
das Wetter ist eine Teilkette von heute ist das Wetter miserabel.
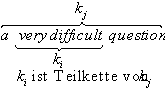
Abb. 4.1. Teilkette
Wir haben Sprache definiert als eine Menge von Sätzen. Was aber ist ein Satz? Darüber
sind ganze Bücher geschrieben worden (z.B. Ries J., Was ist ein Satz? [Ries
1931], Seidel E., Geschichte und Kritik der wichtigsten Satzdefinitionen
[Seidel 1935]), und es wurden an die 200 verschiedene Satzdefinitionen gezählt.
Im Linguistischen Wörterbuch von Lewandowki finden wir u.a.
[Der Satz ist eine] grammatisch, intonatorisch und inhaltlich nach den Regularitäten
der jeweiligen Sprache linear und hierarchisch organisierte Einheit als Mittel zu
Ausdruck, Darstellung und Appell, zur Kommunikation von Vorstellungen oder Gedanken
über Sachverhalte.
(Lewandowski 1990, s.v. Satz)
In dieser Charakterisierung werden einige Eigenschaften von Sätzen genannt, z.B.
daß Sätze Zeichen sind, wobei auf das Organonmodell von Karl Bühler Bezug genommen
wird (vgl. das Kapitel Semiotik). Eine vollständige Charakterisierung des
Begriffes Satz läßt sich nicht auf diese einfache Weise bewerkstelligen. Wir müssen
vielmehr eine vollständige Theorie konstruieren, die bestimmt, welche Objekte Sätze
einer bestimmten Sprache sind. Solch eine Theorie wird Grammatik genannt. Mit anderen
Worten, die Antwort auf die Frage ‘Was ist ein englischer Satz?’ ist
eine Grammatik der englischen Sprache.
Der Begriff Grammatik wird häufig mit einer systematischen Ambiguität gebraucht.
Zum einen ist damit das mental repräsentierte sprachliche Wissen gemeint,
über das ein kompetenter Sprecher einer Sprachgemeinschaft verfügt, und das es ihm
ermöglicht, Sätze seiner Sprache zu verwenden und Äußerungen zu beurteilen (internalisierte
Grammatik). Zum anderen ist damit die Beschreibung oder Theorie des jeweiligen sprachlichen
Wissens gemeint.
Definition 4.7. Grammatik
Eine Grammatik ist eine Theorie einer Einzelsprache.
Die Grammatik einer Sprache als Theorie dieser Sprache spezifiziert, welche Wortketten
Sätze (d.h. grammatische Ketten) dieser Sprache sind, und welche nicht (letztere
heißen ungrammatisch). Die Grammatik des Englischen hätte zu spezifizieren, daß
The killer is called acid rain grammatisch (oder wohlgeformt) ist, während
*is acid the called rain killer ungrammatisch ist, obwohl beide Ketten aus
den gleichen Wörter bestehen. Es gibt bestimmte Konventionen zur Kennzeichnung des
Wohlgeformtheitsgrades eines Ausdrucks. Ein einfacher Stern ‘*’ bedeutet
"ungrammatisch". Bei Bedarf kann weiter differenziert werden:
? fragwürdig * ungrammatisch
?? sehr fragwürdig ** "Müll"
Grammatikalität ist ein relativer Begriff. Eine Kette kann nur unter Bezug auf eine
gegebene Grammatik als grammatisch oder ungrammatisch beurteilt werden. Genauer
müßte man daher sagen, daß die Kette The killer is called acid rain grammatisch
ist bezüglich der Grammatik des Englischen. Sie wäre z.B. ungrammatisch bezüglich
der Grammatik des Deutschen. Nehmen wir ein weiteres Beispiel: Angenommen, ein Kind
äußert den Ausdruck John taked my book. Da die Form *taked in normalem
Englisch nicht existiert, muß das Kind eine ihm eigene Regel angewandt haben, nach
der die Vergangenheitsform durch Anhängen der Endung -ed an den Stamm gebildet
wird. Der Äußerung liegt also eine Grammatik zugrunde, die das Kind internalisiert
hat und die sich von der Erwachsenengrammatik unterscheidet. Mit anderen Worten,
der Ausdruck John taked my book ist grammatisch bezüglich der internalisierten
Grammatik des Kindes und ungrammatisch bezüglich der Grammatik des Englischen.
Die Strukturabhängigkeit grammatischer Prozesse
Bei der Erörterung des Kompetenzbegriffs im ersten Kapitel wurde ausgeführt, daß
sich die grammatische Kompetenz u.a. darin manifestiert, daß der kompetente Sprecher/Hörer
in der Lage ist, Urteile über die Wohlgeformtheit oder Grammatikalität von Ausdrücken
abzugeben und zu entscheiden, ob ein vorgegebener Ausdruck ein Satz seiner Sprache
ist oder nicht. Eine wesentliche Aufgabe einer Grammatik als Theorie einer bestimmten
Sprache ist es daher, die Eigenschaften zu bestimmen, welche in dieser Sprache Sätze
von Nicht-Sätzen unterscheiden. Wie die Beispiele (4.5.)(a) und (b) zeigen, ist
eine derartige Eigenschaft sicher die Anordnung der Wörter. Die Reihenfolge der
Wörter eines Satzes kann nicht beliebig verändert werden. Es entstehen entweder
Sätze mit anderer Bedeutung oder ungrammatische Ausdrücke:
|
(4.6.)
|
(a) John is in the garden (Aussage)
|
|
|
(b) Is John in the garden (Frage)
|
|
|
(c) * Is in the garden John (ungrammatisch)
|
|
|
(d) ** garden in the is John ("Müll")
|
Die bloße lineare Anordnung ist aber nur ein Aspekt. Man betrachte die folgenden
Beispiele:
|
(4.7.)
|
(a) The student found the solution to the problem
|
|
|
(b) The student drove the professor to the station
|
Oberflächlich betrachtet scheinen diese Sätze die gleiche Struktur aufzuweisen:
the - student - Verb - the - Nomen - to - the - Nomen.
Aber ist die Beziehung zwischen to und dem vorangehenden Nomen in solution
to und professor to wirklich die gleiche? Die meisten Muttersprachler
würden wohl zugeben, daß die Verbindung im ersten Fall wesentlich enger ist als
im zweiten. Dieses Gefühl wird durch die Tatsache bestätigt, daß wir die Kette the
professor im zweiten Satz weglassen können, nicht aber die Kette the solution
im ersten:
|
(4.8.)
|
(a) * The student found to the problem
|
|
|
(b) The student drove to the station.
|
Das scheint darauf hinzudeuten, daß im zweiten Fall eine enge Verbindung zwischen
dem Verb drove und der Präposition to besteht.
In der folgenden Konstruktion mit sog. "Pseudo-Spaltsätzen" (engl. pseudo-cleft
sentences), die häufig als "Diagnoseinstrument" der grammatischen
Analyse verwendet wird, fungiert die auf das Verb was (oder eine andere Form
von be) folgende Teilkette als syntaktische Einheit. Die Abweichung von (4..)(b)
weist darauf hin, daß die Kette the professor to the station keine syntaktische
Einheit bildet.
|
(4.9.)
|
(a) What the student found was the solution to the problem
|
|
|
(b) * What the student drove was the professor to the station
|
|
|
(c) What the student drove to the station was the professor
|
Eine ähnliche Konstruktion ist die der sog. Spaltsätze (engl. cleft sentences).
Sie beginnen normalerweise mit dem Pronomen it, gefolgt von einer Form von
be, worauf eine Satzteil folgt, der "hervorgehoben" wird. Im Anschluß
daran steht eine relativsatzähnliche Konstruktion. Wichtig für unsere diagnostischen
Zwecke ist, daß zwischen be und dem Relativpartikel (z.B.that oder
who) eine Konstituente steht.
|
(4.10.)
|
(a) It was the solution to the problem that the student found.
|
|
|
(b) * It was the professor to the station that the student drove.
|
|
|
(c) It was the professor that the student drove to the station.
|
Die bisherige Analyse wird auch durch das Verhalten des Satzes bei der Bildung des
Passivs bestätigt. Es ist ein traditionelles Verfahren, die Bildung des Passivs
dadurch zu beschreiben, daß man die Passivsätze durch bestimmte Veränderungen aus
Aktivsätzen ableitet. Dazu gehört beispielsweise, daß das direkte Objekt des Aktivsatzes
zum Subjekt des Passivsatzes wird (jemand brachte die Zeitung →
die Zeitung wurde gebracht). Dabei gilt nun, daß nur syntaktische
Einheiten (d.h. Konstituenten) bewegt werden können.
|
(4.11.)
|
(a) The solution to the problem was found by a student
|
|
|
(b) * The professor to the station was driven by a student
|
|
|
(c) The professor was driven to the station by a student
|
Die Analyse dieser Beispiele zeigt, daß die Wörter in einem Satz nicht nur wie die
Perlen in einer Kette aufgereiht sind; vielmehr sind bestimmte Wörter enger miteinander
verknüpft als andere, was im folgenden Beispiel durch die Klammerung ausgedrückt
wird:
|
(4.12.)
|
(a) [The student] found [the solution to the problem]
|
|
|
(b) [The student] drove [the professor] [to the station]
|
Definition 4.8. Strukturabhängigkeit
Das Prinzip der Strukturabhängigkeit ist ein Prinzip der modernen Sprachtheorie,
das davon ausgeht, daß das sprachliche Wissen eines Sprechers auf strukturellen
Relationen zwischen Satzelementen basiert und nicht auf der bloßen linearen Anordnung.
Ein weiteres Beispiel möge dieses Prinzip der Strukturabhängigkeit erläutern. Für
die Struktur deutscher Hauptsätze gilt die Regel, daß das finite Verb, d.h. die
nach Person, Numerus und Tempus flektierte Form des Verbs, die zweite Position einnimmt:
(4.13.) Klaus ißt gerne Hamburger
Aber was heißt eigentlich zweite Position? Die Vermutung, daß damit das zweite Wort
im Satz gemeint sein könnte, wird durch die folgenden Beispiele schnell widerlegt:
(4.14.)
 ißt
gerne Hamburger
ißt
gerne Hamburger
Weitere Beispiel würden deutlich machen, daß es hinsichtlich der Zahl der Wörter,
die vor dem finiten Verb stehen können, keinerlei Beschränkungen gibt. Entscheidend
ist, daß die Wortfolge vor dem Verb eine syntaktische Einheit bildet. Wenn man von
der Zweitstellung des Verbs im deutschen Hauptsatz spricht, bezieht man sich auf
solche — möglicherweise sehr komplexe — syntaktische Einheiten. Daraus
ergibt sich jedoch zwangsläufig die Notwendigkeit, zu bestimmen, was eine syntaktische
Einheit von einer beliebigen Wortfolge unterscheidet.
Konstituenz
Die Struktur von Sätzen ist also nicht bloß linear, sie ist hierarchisch. Abgesehen
von Wörtern als den elementaren Bausteinen von Sätzen, fungieren bestimmte Wortketten
als komplexe syntaktische Einheiten. Diese Einheiten werden Syntagmen oder Konstituenten
genannt.
Definition 4.9. Syntagma
Ein Syntagma ist eine einfache oder komplexe (aus mehreren Wörtern bestehende) syntaktische
Einheit.
Definition 4.10. Konstituente
Als Konstituente bezeichnet man in der strukturellen Satzanalyse jede sprachliche
Einheit (Morphem, Wort, Syntagma), die Teil einer größeren sprachlichen Einheit
ist.
So würde man sagen, daß in den zur Diskussion stehenden Sätzen die Ketten the student,
the professor, the solution to the problem jeweils Konstituenten oder Syntagmen
sind.
Ein weiterer grundlegender Begriff ist der der unmittelbaren Konstituente.
Definition 4.11. unmittelbare Konstituente
Unmittelbare Konstituenten sind die maximalen Konstituenten einer Konstruktion.
So werden wir sagen, daß der Satz
(4.15.) The voters sought the safety of the center
aus den unmittelbaren Konstituenten the voters und sought the safety of the
center besteht. Das kann auf folgende Weise dargestellt werden:

Abb. 4.2. Unmittelbare Konstituenten
Die Verbindungslinien (Kanten, Äste oder Zweige) repräsentieren (von unten nach
oben) die Relation "X ist unmittelbare Konstituente von Y".
Natürlich sind andere Analysen denkbar. Man mag einwenden, daß in der Schulgrammatik
die Struktur des Satzes als Subjekt Prädikat Objekt (S P O) wiedergegeben
würde, d.h. die unmittelbaren Konstituenten wären [the voters]S
[sought]P [the safety of the center]O. In der
Tat sind [the voters], [sought], und [the safety of the center] Konstituenten des
Satzes (s.u.) und sie füllen bestimmte syntaktische Positionen (sie haben bestimmte
grammatische Funktionen). Es werden in der Schulgrammatik jedoch keine weiteren
Aussagen über die Konstituenz im hier gemeinten Sinne gemacht. Nichts spricht gegen
die Anordnung von S P O als S [P O], d.h. unser Satz hätte die Struktur
[the voters]S [[sought]P [the safety of the
center]O]. Es kann gezeigt werden, daß zwischen dem Verb und dem
Objekt ein enger Zusammenhang besteht. Beispielsweise kann man das Objekt nicht
einfach weglassen.
(4.16.) * The voters sought
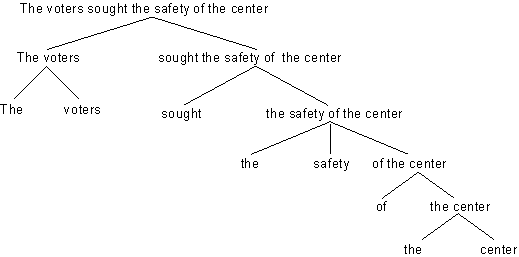
Abb. 4.3. Konstituenz als Baumdiagramm
Das spricht auch gegen die Aufteilung [the voters sought] [the safety of the center]:
[the voters sought] ist keine Konstituente. Der folgende Satz läßt sich umgekehrt
nicht durch ein Objekt ergänzen:
(4.17.) The voters hesitated vs. * The voters hesitated the candidates
Mit der Pseudo-Spaltsatz-Konstruktion läßt sich hingegen die Verbindung von Verb
und Objekt als Konstituente nachweisen:
(4.18.) What the voters have done is (to) seek the safety of the center
Die vorangehende Analyse hat bereits gezeigt, daß auch die Kette sought the safety
of the center aus den unmittelbaren Konstituenten sought und the safety
of the center besteht. Durch die Ermittlung aller unmittelbaren Konstituenten
der jeweils höheren Konstituente erzielt man eine vollständige hierarchische Gliederung
eines gegebenen Satzes. Diese Methode der Analyse von Sätzen in unmittelbare Konstituenten
wird IC-Analyse genannt, nach dem englischen immediate constituent analysis.
Die IC-Analyse unseres Beispielsatzes liefert das in Abb. 4.3. gezeigte Ergebnis.
Es gibt eine Reihe weiterer Notationsformen für die Darstellung der Konstituenz
von Sätzen, so z.B. verschachtelte Klammern oder Kästchen. Die Konstituenz unseres
Beispielsatzes kann demnach folgendermaßen durch einen Klammerausdruck oder ein
Kastendiagramm dargestellt werden:
[[[The][voters]][[sought][[the][[safety][[of][[the][center]]]]]]
Abb. 4.4. Konstituenz als Klammerausdruck

Abb. 4.5. Konstituenz als Kastendiagramm
Alle Syntagmen, die in einem Satz irgendwo als unmittelbare Konstituenten fungieren,
sind Konstituenten des Satzes. Präziser läßt sich der Begriff Konstituente wie folgt
definieren:
Definition 4.12. Konstituente
1. Eine Kette ki ist eine Konstituente einer Kette kj wenn
sie eine unmittelbare Konstituente dieser Kette ist.
2. ki ist eine Konstituente von kj wenn sie eine unmittelbare
Konstituente einer Kette kk ist, die ihrerseits Konstituente von kj
ist.
So ist z.B. house in [[behind] [[the][house]]] eine Konsituente von behind
the house, weil es eine unmittelbare Konstituente von the house ist,
welches seinerseits eine unmittelbare Konstituente von behind the house ist:
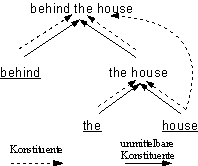
Abb. 4.6. Konstituente von
Definition 4.13. Terminale Konstituente
Konstituenten, die nicht weiter in unmittelbare Konstituenten zerlegt werden können,
sind terminale Konstituenten oder Endkonstituenten.
Die Wörter behind, the und house im obigen Beispiel sind terminale
Konstituenten.
Methoden zur Satzanalyse
Die Aufteilung von sprachlichen Ausdrücken in Konstituenten erfolgte in unseren
Beispielen meist nach rein intuitiven Gesichtspunkten, d.h. nach dem Sprachgefühl.
So entspricht die Zerlegung von [behind the house] in die unmittelbaren Konstituenten
[behind] und [the house] sicher mehr unserer Intuitition als etwa
in [behind the] und [house]. Es ist aber wünschenswert, diese intuitiv
erkannten Gesetzmäßigkeiten zu objektivieren. Im folgenden werden dazu einige analytische
Verfahren vorgestellt, deren Anwendung eine zumindest vorläufige Analyse der Konstituentenstruktur
eines Satzes liefert. Im Gegensatz zu einer rein intuitiven Vorgehensweise sind
diese Verfahren formal expliziter und wissenschaftlich nachkontrollierbar und demnach
objektiver und zuverlässiger.
Für viele amerikanische Strukturalisten der post-Bloomfieldschen Ära war das Hauptanliegen
ihrer Forschungsarbeit die Entwicklung eines Inventars von Standardmethoden, die
bei der sprachwissenschaftlichen Analyse anzuwenden seien. Man ging von der Annahme
aus, daß Sprachen (aufgefaßt als ein "Korpus", d.h. eine Kollektion von
tatsächlichen sprachlichen Äußerungen) eine Struktur aufweisen, die es "aufzudecken"
galt. Daher erhielten diese Methoden den Namen discovery procedures ("Aufdeckungsverfahren").
Es wurde angenommen, daß man durch die Anwendung dieser Verfahren auf eine Menge
von beobachteten Äußerungen (ein sogenanntes Korpus) unter minimaler Heranziehung
von Informantenurteilen über die ‘Gleichheit’ und ‘Verschiedenheit’
von Ausdrücken mit Sicherheit die Regeln der Grammatik aus dem Korpus ableiten könne.
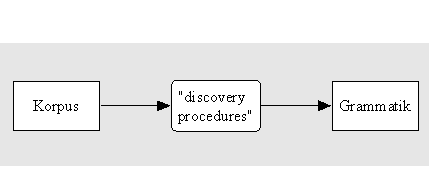
Abb. 4.7. "Discovery Procedures"
Die grundlegenden Verfahren dabei sind die Segmentierung, d.h. die Zerlegung einer
Äußerung in linear aufeinanderfolgende diskrete Segmente, und die Klassifizierung
dieser Segmente nach verschiedenen Kriterien. Diese vorrangige Beschäftigung mit
Fragen der Methodologie drückt sich auch in der Art der Begriffsbildung aus. Begriffe
werden mit Vorliebe "operational" definiert, das heißt unter Angabe von
Kriterien zur Identifizierung von Objekten, die unter den Begriff fallen. So fällt
in gewisser Weise Theorie und Methode zusammen.
Die im folgenden vorgestellten Verfahren haben nicht diesen theoretischen Status;
sie sind lediglich Hilfsverfahren zur Bildung begründeter Hypothesen über die syntaktische
Struktur von sprachlichen Ausdrücken. Sie basieren letztlich auf dem eingangs angesprochenen
Prinzip der Strukturabhängigkeit sprachlicher Prozesse.
Eine Reihe nützlicher Verfahren zur operationalen Satzanalyse hat in den sechziger
Jahren der Germanist H. Glinz entwickelt (Glinz 1965). Sie sind als "Proben"
verschiedener Art bekannt geworden: Austauschprobe, Ersatzprobe, Umstellprobe, Verschiebeprobe,
Weglaßprobe, Erweiterungsprobe, Umformungsprobe. Die international üblichen Termini
dafür sind:
- Substitution (Austauschprobe, Ersatzprobe);
- Permutation (Umstellprobe, Verschiebeprobe);
- Reduktion oder Tilgung (Weglaßprobe);
- Expansion (Erweiterungsprobe);
- Transformation (Umformungsprobe).
Substitution (Austausch- oder Erstatzprobe)
Eines der wichtigsten Verfahren in der Linguistik überhaupt ist das der kontrollierten
Substitution oder Kommutation. Es wird nicht nur in der Satzanalyse angewandt sondern
auf allen sprachlichen Ebenen. Elemente, die in einem gegebenen Kontext austauschbar
sind (kommutieren), werden als Elemente der gleichen Klasse betrachtet.
Bei Anwendung der Substitution in der Satzanalyse wird in einer gegebenen Kette
eine Teilkette durch eine andere Teilkette ersetzt; der Rest der Kette muß dabei
konstant gehalten werden, und die durch die Substitution neu entstandene Kette darf
nicht ungrammatisch sein. Die Teilketten, die auf diese Art ermittelt werden, haben
dieselbe Distribution (Menge von Kontexten); sie gehören zum gleichen syntaktischen
Paradigma und können gegebenenfalls Konstituenten sein.
(4.19.)

Da die Teilketten in der geschweiften Klammer in (4.19.) alle für einander ersetzt
werden können, ohne daß der Satz dadurch ungrammatisch würde, liegt die Hypothese
nahe, daß jede der eingeklammerten Teilketten eine Konstituente bildet.
Substitution
Teilketten, die in gleicher syntaktischer Position in einer gegebenen Kette austauschbar
sind, ohne daß die neu entstandene Kette ungrammatisch ist, können gegebenenfalls
Konstituenten sein.
Die etwas vorsichtige Formulierung dieser Prozedur ist mit Bedacht gewählt, da der
Substitutionstest nicht automatisch korrekte Analysen erzeugt:
(4.20.) The old

Anhand des Substitutionstests könnten auch in Beispiel (4.20.) die in der geschweiften
Klammer stehenden Teilketten als Konstitutenten gelten. Eine solche Analyse widerspricht
jedoch jeglicher Intuition über Konstituenz; niemand würde die eingeklammerten Teilketten
als Konstituenten bezeichnen. Eine Möglichkeit, diesem Problem zu begegnen und Ergebnisse
zu erzielen, die intuitiv nachvollziehbarer sind, ist, den Substitutionstest unter
einem quantitativen Gesichtspunkt anzuwenden. Das soll heißen, daß beim Substitutionstest
auch darauf geachtet wird, wieviele Syntagmen ein Paradigma umfasst und in wievielen
verschiedenen Umgebungen ein Paradigma vorkommen kann. So ist das Paradigma in (4..)
einfacher und problemloser um weitere Syntagmen zu vergrößern, als das in Beispiel
(4.20.) der Fall ist. Besonders deutlich wird der quantitative Aspekt in unseren
Beispielen hinsichtlich der Frage der möglichen Umgebungen, in denen die jeweiligen
Paradigmen vorkommen können. Während das Paradigma in (4..) in einer Vielzahl möglicher
Positionen stehen kann (vgl. (4..), ist es für das Paradigma in (4.20.) schwierig,
andere geeignete Kontexte zu finden.
(4.21.)

Für sich genommen reicht der Substitutionstest nicht aus, um eine befriedigende
Satzanalyse zu erzeugen. In der tatsächlichen Anwendung muß er von der Intuitition
überprüft und vor allen Dingen durch andere Verfahren ergänzt werden.
Ein weiteres Verfahren zur Satzanalyse ist der Pronominalisierungstest.
Pronominalisierung
Die Teilketten, die pronominalisiert, d.h. durch Pro-Formen substituiert werden
können, sind Konstituenten
Hierbei soll untersucht werden, auf welche Teilketten in einer gegebenen Kette man
sich mit einer Pro-Form beziehen kann. Die Pronominalisierung kann als eine Art
Substitution betrachtet werden.
|
(4.22.)
|
(a) Sherlock Holmes and Dr. Watson lived in Bakerstreet. They were
good friends.
|
|
|
(b) Sherlock Holmes and Dr. Watson lived in Bakerstreet. They stayed there
for many years.
|
|
|
(c) Sherlock Holmes and Dr. Watson like music. So do I.
|
In diesen Beispielen werden die Pro-Formen they, there und so
benutzt, um sich jeweils auf Sherlock Holmes and Dr. Watson, in Bakerstreet
und like music zu beziehen. Demzufolge ist anzunehmen, daß es sich bei diesen
Teilketten um Konstituenten handelt. Mithilfe des Pronominalisierungstestes kann
auch in Bezug auf die Beispiele in (4..) und (4..) eine präzisere Aussage hinsichtlich
der Konstituenz getroffen werden; die Teilketten in (4..) können nämlich pronominalisiert
werden:
(4.23.) They cut the grass.
Dahingegen findet sich für keine der Teilketten in (4..) eine Pro-Form, was die
Hypothese stützt, daß es sich bei diesen wohl nicht um Konstituenten handelt. Aber
auch der Pronominalisierungstest ist nur von begrenzter Gültigkeit, da es nicht
für alle Ketten, die intuitiv als Konstituenten gewertet würden, Pro-Formen gibt.
Eine weitere Möglichkeit zur Ermittlung von Konstituenten ist die Anwendung des
Fragetests. Er kann ebenfalls als eine Art Subsitutionstest aufgefaßt werden:
Fragetest
Die Teilketten, nach denen sich fragen läßt, sind Konstituenten.
|
(4.24.)
|
(a) Who is coming today? — My mother.
|
|
|
(b) When is she coming? — Next Saturday.
|
|
|
(c) Where did you put the book? — On the table.
|
|
|
(d) Where are you going? — To London.
|
|
|
(e) How did you like the mushrooms? — Very well.
|
|
|
(f) What are you talking about? — The advantages of literacy.
|
|
|
(g) Why does Jack smoke so much? — Because he is an addict.
|
Tilgung (Weglaßprobe)
Tilgung
Teilketten, die in einer elliptischen Konstruktion gestrichen werden können, sind
Konstituenten.
Beim diesem Test geht es darum, zu sehen, welche Teilketten in einer gegeben Kette
gestrichen werden können, ohne daß sich am Verständnis des Ganzen etwas ändert.
Eine elliptische Konstruktion ist eine wohlgeformte Konstruktion, in der bestimmte
Teilketten unausgedrückt sind.
|
(4.25.)
|
(a) John won't wash the dishes — I bet he will wash the dishes
if you're nice to him.
|
|
|
(b) John won't help me with my homework, but his brother will help
me with my homework
|
Die Weglaßprobe ist auch nützlich, um für einen gegebenen Satz das "syntaktische
Minimun" zu ermitteln und spielt insbesondere für die Ermittlung von Dependenzbeziehungen
eine wichtige Rolle (s.u.).
Koordination
Ein wichtiges und besonders zuverlässiges Verfahren der Satzanalyse ist der Koordinationstest.
Koordination bedeutet in diesem Zusammenhang die Verknüpfung von Teilketten mithilfe
von Konjunktionen wie z.B und. Die Konstituenten, die mithilfe dieses Verfahrens
ermittelt werden, gehören zum gleichen Typ.
Koordinationstest
Die Teilketten, die durch Konjunktion miteinander koordiniert werden können, sind
Konstituenten, und zwar Konstituenten desselben Typs.
|
(4.26.)
|
(a) Long speeches and rainy days are depressing
|
|
|
(b) John gave a very clever and hardly trivial answer.
|
|
|
(c) Do you know the man next door and his girlfriend?
|
Der Koordinationstest legt nahe, daß die kursiv gesetzten Teilketten Konstituenten
sind. In dem nun folgenden Beispiel
|
(4.27.)
|
(a) John ran up the hill. John ran up the stairs.
|
|
|
(b) John ran up the hill and up the stairs.
|
ermitteln wir duch den Koordinationstest die Konstituenten up the hill und
up the stairs. Der folgende Beispielsatz (4..) (a) hat, oberflächlich betrachtet,
dieselbe Struktur wie (4.27.) (a), es scheint daher plausibel, anzunehmen, daß es
sich auch bei up his mother und up his sister um Konstituenten handelt,
die koordiniert werden können:
|
(4.28.)
|
(a) John rang up his mother. John rang up his sister.
|
|
|
(b) * John rang up his mother and up his sister.
|
Das Ergebnis zeigt aber, daß dies nicht der Fall ist, die Koordination von up his
mother und up his sister führt zu einer Kette, die nicht wohlgeformt
ist. Das heißt, daß zwar die Teilketten up the hill und up the stairs
Konstituenten sind, up his mother und up his sister dagegen nicht.
Dieser Analyse wird durch die Klammerung Rechnung getragen: [John] [ran]
[up the hill] im Gegensatz zu [John] [rang up] [his mother].
Daß die miteinander koordinierten Konstituenten zum selben Typ gehören müssen, zeigt
das nächste Beispiel:
(4.29.)
|
(a) John wrote to Mary and to Fred.
|
|
|
(b) John wrote a postcard and a letter.
|
|
|
(c) * John wrote a letter and to Fred.
|
|
|
(d) * John wrote to Mary and a postcard
|
In (4.29.) (a) und (b) haben die koordinierten Konstituenten jeweils die gleiche
Struktur, nämlich Präposition – Nomen in (a) und Artikel – Nomen in
(b). In den Sätzen (4.29.) (c) und (d) gehören die koordinierten Konstituenten nicht
zum selben Typ, das Ergebnis ist eine nicht wohlgeformte Kette.
Permutation (Umstellprobe oder Verschiebeprobe)
Die Permutation ist eine Operation, welche die Reihenfolge (die lineare Anordnung)
von Wörtern bzw. Wortgruppen im Satz verändert.
Verschiebeprobe
Nur Konstituenten können von einer Position innerhalb einer Kette zu einer anderen
Position verschoben werden
Dazu das folgende Beispiel:
|
(4.30.)
|
(a) I don't like your elder sister.
|
|
|
(b) Your elder sister, I don't like (though your brother is OK).
|
Diese Art der Umstellung von Konstituenten in einem Satz erfüllt oftmals eine rhetorische
Funktion, insbesondere, wenn die vorangestellte Sequenz durch eine andere kontrastiert
wird, wie in (4.30.) (b). Zusätzliche Beispiele sind:
|
(4.31.)
|
(a) That kind of attitude, I simply cannot understand.
|
|
|
(b) Most of these problems a computer could easily solve.
|
|
|
(c) This topic we will take up again in the section.
|
Eine Konstituente kann nur ganz und nicht etwa teilweise bewegt werden:
|
(4.32.)
|
(a) Your elder sister, I don't like.
|
|
|
(b) * Your elder, I don't like sister.
|
|
|
(c) * Elder sister, I don't like your.
|
|
|
(d) * Sister, I don't like your elder.
|
|
|
(e) * Your, I don't like elder sister.
|
Neben den oben angesprochenen allgemeineren Verfahren können häufig spezifische
einzelsprachliche Konstruktionen zur "Diagnose" herangezogen werden. Für
das Englische haben wir beispielsweise bereits die Spaltsätze (It was John who used
my tooth brush) und Pseudo-Spaltsätze (What annoys me about John is his dishonesty)
sowie die Aktiv-Passiv-Beziehung kennengelernt.
Beispiel
Im nun folgenden Beispiel geht es um die Anwendung einiger der oben vorgestellten
Methoden; es soll mit ihnen die gesamte Konstituentenstruktur des Satzes
(4.33.) The vase stood on the table
ermittelt werden.
|
(4.34.)
|
(a) It stood on the table. (It=The vase, Pronominalisierung)
|
|
|
(b) What stood on the table was the vase (Pseudo-Spaltsatz)
|
|
|
(c) Where did the vase stand? On the table (Fragetest)
|
|
|
(d) What the vase stood on was the table. (Pseudo-Spaltsatz)
|
|
|
(e) The vase stood on the table and looked splendid. (Koordination)
|
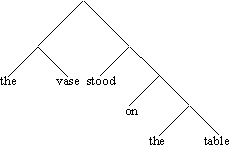
Damit sind die Wortketten the vase, on the table, the table, stood on the table
als Konstituenten ausgewiesen. Da die einzelnen Wörter ebenfalls (terminale) Konstituenten
sind, ergibt sich rein logisch nur eine mögliche Konstituentenstruktur:
Dependenz
Wir haben gesehen, daß in einem Satz einige Wörter enger miteinander verknüpft sein
können als andere, und daß einige Wörter oder Ketten ausgelassen werden können,
ohne daß die Gesamtstruktur zerstört wird, während dies bei anderen nicht der Fall
ist. Wir können dieser Tatsache einerseits durch den Begriff der Konstituenz Rechnung
tragen, wie wir oben gesehen haben. Im folgenden soll eine andere wichtige syntaktische
Relation besprochen werden, die Dependenz oder Abhängigkeit.
Wenn wir das analytische Verfahren der Tilgung (Weglaßprobe) auf bestimmte Beispiele
anwenden, stellen wir fest, daß gewisse Wörter nur gleichzeitig mit anderen weggelassen
werden können. Zum Beispiel können wir in dem Satz
(4.35.) The students solved extremely difficult problems
das Adjektiv difficult nur weglassen, wenn wir auch das Adverb extremely
tilgen:
|
(4.36.)
|
* The students solved extremely difficult problems
|
|
|
The students solved extremely difficult problems
|
|
|
The students solved extremely difficult problems
|
|
|
* The students solved (extremely) difficult problems
|
Andersherum setzt das Adverb extremely die Anwesenheit des Adjektivs difficult
voraus. Wir werden sagen, daß extremely vom Adjektiv difficult Abhängig
ist. Das Adjektiv ist seinerseits vom Nomen problems abhängig. Diese Beziehung
der Abhängigkeit wird Dependenz genannt.
Definition 4.14. Dependenz
Dependenz ist eine zweistellige Relation zwischen zwei Wörtern w1
und w2 in einer Kette, wobei das Vorkommen oder die Form oder
allgemein das grammatische Verhalten von w1 durch w2
kontrolliert wird.
Definition 4.15. Dependens
Ist w1 von w2 abhängig, dann nennt man w1
das Dependens.
Definition 4.16. Rektion
Rektion ist die Umkehrung der Dependenzrelation. Gegeben seien zwei Elemente w1
und w2: wenn w2 von w1 abhängig
ist, dann regiert w1 das w2.
Definition 4.17. Regens
Das kontrollierende Element in einer Dependenzrelation soll Regens genannt werden.
In unserem Beispiel wird das Vorkommen von extremely durch difficult
kontrolliert, d.h. extremely ist von difficult abhängig; das Vorkommen
von difficult wird durch das Nomen problems kontrolliert. Im Syntagma
terribly sorry, wo terribly von sorry abhängig ist, ist sorry
das Regens von terribly; sorry regiert terribly.
Ähnlich wie die Konstituenz kann die Dependenz durch Diagramme veranschaulicht werden.
Die Dependenzrelation bzw. ihre Umkehrung, die Rektion, wird durch eine Kante angezeigt,
die das Dependens nach oben mit dem Regens verbindet. Durch das horizontale Versetzen
von Dependens (hier: extremely) und Regens (hier: difficult) wird
gleichzeitig die Präzedenzrelation (engl. precedence) ausgedrückt, d.h. die
Tatsache, daß in der linearen Abfolge extremely vor difficult steht:

Abb. 4.9. Dependenzstruktur
Im obigen Beispiel ging es darum, daß das Vorkommen eines Elementes vom Vorkommen
eines anderen abhängig ist. Ein andere Art der Abhängigkeit liegt vor, wenn die
grammatische Form eines Elements von den Eigenschaften eines anderen abhängig ist.
Im Deutschen z.B. wird nicht nur das Vorkommen, sondern auch die Form des attributiven
Adjektivs z.B. hinsichtlich der Kategorien Genus ("Geschlecht", d.h. Makulinum,
Femininum, Neutrum), Numerus (Einzahl, Mehrzahl), und Kasus (Nominativ, Genitiv,
Dativ, Akkusativ) durch das Nomen kontrolliert. Im Falle des Genus ist dies besonders
deutlich zu sehen, weil bei Nomina das Genus ein "inhärentes", d.h. dem
jeweiligen Nomen innewohnendes Merkmal ist, während Adjektive von sich aus nicht
genusmarkiert sind, sondern sich nach dem inhärenten Genus des Nomens richten.
|
(4.37.)
|
ein schönes Bild (das Bild) (Neutrum Singular)
|
|
|
ein schöner Garten (der Garten) (Maskulinum Singular)
|
|
|
eine schöne Blume (die Blume) (Femininum Singular)
|
|
|
die schönen Blumen (die Blumen) (Femininum Plural)
|
Das Verb kontrolliert die Kasusform seiner Komplemente (Ergänzungen):
|
(4.38.)
|
der Ritter begegnete einem Monster (Dativ)
|
|
|
er erschlug den Drachen (Akkusativ)
|
|
|
er harrte der Dinge... (Genitiv)
|
Präpositionen kontrollieren ebenfalls die Kasusform ihrer Komplemente:
|
(4.39.)
|
gegen den Strom (Akkusativ)
|
|
|
mit dem Strom (Dativ)
|
|
|
außer der Reihe (Genitiv).
|
Eine besondere Situation liegt bei der Beziehung zwischen Subjekt und Hauptverb
eines Satzes vor. Man kann zum Beispiel argumentieren, daß hinsichtlich bestimmter
grammatischer Eigenschaften (z.B. Numerus, Person) das Subjekt eines Satzes die
Form des finiten Verbs kontrolliert:
|
(4.40.)
|
Ich singe (4. Person Singular)
|
|
|
Du singst (2. Person Singular)
|
|
|
Er singt (3. Person Singular)
|
|
|
Sie singen (3. Person Plural)
|
In dieser Hinsicht kann man sagen, daß das Verb vom Subjekt abhängt. Es gibt jedoch
andere Merkmale, wo die Annahme plausibler ist, daß das Verb das Subjekt kontrolliert.
So verlangen z.B. bestimmte Verben, daß das Nomen des Subjekts zu einer besonderen
semantischen Klasse gehört, z.B. die Klasse der Nomina, die Lebewesen bezeichnen,
die intentional handeln können.
|
(4.41.)
|
(a) The boy admires sincerity
|
|
|
(b) * Sincerity admires the boy
|
|
|
(c) The mother admires the boy
|
Die Ungrammatikalität von (4.41.)(b) beruht darauf, daß das Verb admire keine
abstrakten Subjekte zuläßt.
Wir müssen also annehmen, daß das Subjekt und das Hauptverb eines Satzes gegenseitig
abhängig sind. Man nennt diese gegenseitige Abhängigkeit Interdependenz.
Definition 4.18. Interdependenz
Wenn bei zwei Elementen w1 und w2 sowohl w1
von w2 als auch w2 von w1
abhängig ist, dann sind w1 und w2 interdependent.
Wir wollen in unseren Dependenzdiagrammen die Interdependenz dadurch ausdrücken,
daß wir die involvierten Elemente auf der gleichen horizontalen Höhe anordnen und
sie mit doppelten Kanten verbinden. In dem Satz Boys admire girls besteht
zwischen boys und admire eine Beziehung der gegenseitigen Abhängigkeit,
girls wird von admire regiert:

Abb. 4.10. Interdependenz
Es wurde bereits darauf hingewiesen, daß die Weglaßprobe ein wichtiges Verfahren
zur Ermittlung der Dependenzstruktur von Sätzen ist. Was übrig bleibt, wenn alle
tilgbaren Wörter und Wortgruppen weggelassen werden, ist die Minimalstruktur des
Satzes. Im folgenden Beispiel
|
(4.42.)
|
(a) A special commission of technical experts proposed a more realistic solution
|
|
|
(b) A special commission of technical experts
proposed a more realistic solution
|
|
|
(c) A commission proposed a solution
|
|
|
(d) Commission proposed solution
|
erhalten wir in (4.42.)(c) die Mimimalstruktur. Im Telegrammstil oder in Zeitungsüberschriften
kann dies weiter wie in (4.42.)(d) reduziert werden, wobei commission und
proposed interdependent sind.
Dafür erhalten wir folgende Abhängigkeitsstruktur
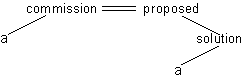
Abb. 4.11.
Das getilgte Adjektiv special ist von commission abhängig. Wir haben
schon ausgeführt, das Präpositionen ihre Komplemente regieren. In der Wortgruppe
of technical experts regiert of das Nomen experts und dieses
wiederum technical. Dafür erhalten wir folgende Teildependenzstruktur.

Abb. 4.12.
Die Gruppe of technical experts ist eine nähere Bestimmung von commission,
hängt also von diesem ab. Analoges gilt für more realistic, das von solution
regiert wird. Für den ganzen Satz erhalten wir damit folgende Dependenzstruktur:
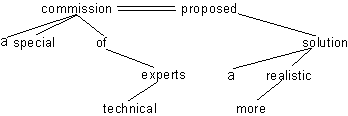
Abb. 4.13.
Wie werden später sehen, daß ein sehr enger Zusammenhang zwischen der Dependenzstruktur
und der Konstituentenstruktur eines Satzes besteht.
Grammatische Kategorien
Konstituentenklassen
Theoretisch würde die fortgesetzte Konstituentenanalyse von Sätzen die Menge der
Konstituenten einer Sprache liefern. Es wäre jedoch dennoch unmöglich, die Menge
der Sätze durch Konstituenten allein formal zu charakterisieren, weil die Menge
der Konstituenten, ebenso wie die Menge der Sätze, nicht endlich ist. Man kann jedoch
zeigen, daß die Konstituenten bestimmte formale und funktionale Eigenschaften gemeinsam
haben, so daß es möglich ist, sie als Elemente der gleichen Klasse aufzufassen.
Die Menge der möglichen Konstituenten kann also in eine begrenzte Zahl von Teilmengen
unterteilt werden, die wir Konstituentenklassen nennen.
Im folgenden Satz zum Beispiel
(4.43.) Peter met the man in the moon
kann Peter durch die Konstituenten the girl, the old man over there
etc. substituiert werden:
|
(4.44.)
|
(a)
|
Peter
|
met the man in the moon
|
|
|
(b)
|
The girl
|
|
|
|
(c)
|
The old man over there
|
|
|
|
(d)
|
The fair-haired baby
|
|
|
|
(e)
|
The rhinoceros we caught last year
|
|
Alle diese untereinander substituierbaren Ausdrücke sind Mitglieder der gleichen
Konstituentenklasse. Eine ihrer gemeinsamen Eigenschaften ist, daß sie in der Umgebung
met the man in the moon kommutieren. Sie können auch die Kette the man in
the moon ersetzen, d.h. in der Umgebung Peter met vorkommen.
|
(4.45.)
|
Peter met
|
the man in the moon
|
(a)
|
|
|
|
the girl
|
(b)
|
|
|
|
the old man over there
|
(c)
|
|
|
|
the fair-haired baby
|
(d)
|
|
|
|
the rhinoceros we caught last year
|
(e)
|
Die Menge der Kontexte oder Umgebungen, in welchen eine sprachliche Einheit vorkommen
kann, nennt man ihre Distribution. Mit dem Begriff der Distribution kann der Begriff
Konstituentenklasse wie folgt definiert werden:
Definition 4.19. Konstituentenklasse
Eine Konstituentenklasse ist eine Menge von Konstituenten, die hinsichtlich ihrer
Distribution (zumindest teilweise) äquivalent sind.
Wir werden noch sehen, daß die gemeinsamen Eigenschaften von Konstituenten einer
bestimmten Klasse wesentlich mit ihrem internen Aufbau zu tun haben.
Lexikalische Kategorien
Es gibt einige Konstituentenklassen, die uns aus der Schulgrammatik vertraut sind.
Es handelt sich um die Wortarten. Diese werden lexikalische Kategorien genannt.
Definition 4.20. lexikalische Kategorie
Die Wortklassen Determinator (D), Nomen (N), Verb (V), Adjektiv (A), Präposition
(P) und Konjunktion (K) sind lexikalische Kategorien.
Die Klasse der Determinatoren (engl. determiners) umfaßt u.a. die Artikel
(the, a/an, some), die Demonstrativpronomina (this, these; that, those)
sowie die Possessivpronomina (my, your, his, her, its, our, their).
Die Wortarten haben eine lange grammatische Tradition (vgl. Robins 1966). Näheres
dazu im Kapitel Morphologie.
|
Wortart
|
Symbol
|
Beispiele
|
|
Nomen (Substantiv)
|
N
|
dog, girl, house, honesty ...
|
|
Verb
|
V
|
jump, sing, kick, study, feel ...
|
|
Adjektiv
|
A
|
bad, good, tall, green, angry
|
|
Determinator
|
D
|
|
|
|
Artikel
|
|
a, an, the
|
|
|
Demonstrativpronomen
|
|
this, that, these, those
|
|
|
Possesivpronomen
|
|
my, your, her, his, its
|
|
Präposition
|
P
|
on, in, under, over, across
|
Abb. 4.14. Lexikalische Kategorien
Syntaktische Kategorien
Wir haben Dependenz als wichtige grammatische Relation kennengelernt und es gibt
Grammatikmodelle, die ausschließlich auf der Dependenzrelation aufbauen (sog. Dependenzgrammatiken,
vgl. Tesnière 1959 (1980), Weber 1992). Die Dependenz kann jedoch auch im Rahmen
der Konstituentenanalyse als methodisches Verfahren zur Identifizierung von Konstituenten
eingesetzt werden. Es gilt folgendes Prinzip:
Ein Regens und alle von ihm kontrollierten abhängigen Elemente bilden zusammen eine
Konstituente.
Wir setzen das Verfahren im folgenden zur Ableitung des Begriffs der syntaktischen
Kategorie ein. Bis jetzt haben wir Dependenz als Relation zwischen Wörtern aufgefaßt.
Der Dependenzbegriff kann und muß so verallgemeinert werden, daß Abhängigkeiten
erfaßt werden, die allgemein zwischen Elementen bestimmter Wortklassen bestehen.
So werden wir sagen, daß in der Kette ein schönes Gemälde die Dependenz des
Wortes schönes von Gemälde eine Instanz der Dependenz eines attributiven
Adjektivs vom Nomen ist. Wir können nun die Dependenzstruktur einer Konstituente
unter Bezug auf die Klassen repräsentieren, der die einzelnen Wörter in der Kette
angehören. Die Knoten in einem Dependenzbaum werden durch die Namen lexikalischer
Kategorien benannt. Wie vorher, repräsentiert die relative horizontale Anordnung
die Präzedenz-Relation (in der Kette A N geht A dem N voraus). Eine gestrichelte
Linie zwischen einem Wort und seiner Kategorie repräsentiert die Relation ‘ist
ein (Element von)’, z.B. ‘auf ist ein P’.
Zum Beispiel:
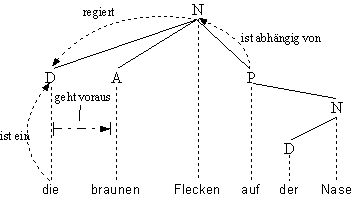
Abb. 4.15. Verallgemeinerte Dependenzstruktur
Auf der Grundlage dieser Verallgemeinerung können wir den Begriff X-Phrase wie folgt
definieren, wobei X eine beliebige lexikalische Kategorie (N, V, A, P, ... ) ist:
Definition 4.21. X-Phrase
Eine regierende lexikalische Kategorie X zusammen mit all ihren Abhängigen konstituiert
eine X-Phrase, abgekürzt XP.
Definition 4.22. lexikalischer Kopf
Die regierende lexikalische Kategorie X einer X-Phrase ist der (lexikalische) Kopf
dieser Phrase.
Hierbei handelt es sich um ein Definitionsschema, das durch Einsetzen einer lexikalischen
Kategorie für X zu einer Definition für eine entsprechende Phrase wird und gleichzeitig
ein Symbol dafür liefert. Ersetzen wir X beispielsweise durch N, dann erhalten wir
etwa folgende Formulierung:
Definition 4.23. N-Phrase (Nominalphrase)
Eine regierende lexikalische Kategorie N zusammen mit all ihren Abhängigen konstituiert
eine N–Phrase, abgekürzt NP, genannt Nominalphrase. Das N ist der Kopf dieser
Phrase.
Im obigen Beispiel ist die gesamte Kette die braunen Flecken auf der Nase
eine N–Phrase (= Nominalphrase, abgekürzt NP).
Definition 4.24. V–Phrase (Verbalphrase)
Eine regierende lexikalische Kategorie V zusammen mit all ihren Abhängigen konstituiert
eine V–Phrase, abgekürzt VP, genannt Verbalphrase. Das V ist der Kopf dieser
Phrase.
Definition 4.25. A–Phrase (Adjektivphrase)
Eine regierende lexikalische Kategorie A zusammen mit all ihren Abhängigen konstituiert
eine A–Phrase, abgekürzt AP, genannt Adjektivphrase. Das A ist der Kopf dieser
Phrase.
Definition 4.26. P–Phrase (Präpositionalphrase)
Eine regierende lexikalische Kategorie P zusammen mit all ihren Abhängigen konstituiert
eine P–Phrase, abgekürzt PP, genannt Präpositionalphrase. Das P ist der Kopf
dieser Phrase.
Die Kette auf der Nase ist eine P–Phrase (=Präpositionalphrase, abgekürzt
PP) und enthält eine weitere NP: der Nase.
Alle X-Phrasen können auch aus dem Kopf alleine bestehen. Ein einzelnes Wort bildet
eine X-Phrase, wenn es die gleiche syntaktische Position wie die entsprechende X-Phrase
einnimmt, d.h. mit einer X-Phrase kommutiert. Das Adjektiv in a tall boy
kommutiert mit very tall: a very tall boy. Das Wort
tall ist also einerseits ein Element der lexikalischen Kategorie Adjektiv:
[tall]A, es ist andererseits der Kopf einer Adjektivphrase, die keine
weiteren Abhängigen hat: [[tall]A]AP.
Der eigentliche Dependenzbaum in Abb. 4.15. repräsentiert nun nicht mehr
nur die Dependenzstruktur einer einzelnen Kette sondern vielmehr die einer Klasse
von Ketten. Die Kette die grünen Männchen auf dem Mars hat die gleiche Dependenzstruktur:
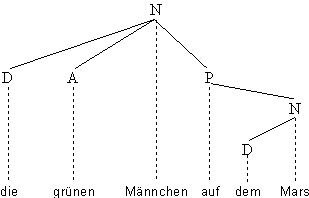
Abb. 4.16.
Über den Begriff der X-Phrase können wir jetzt auch systematisch einen Zusammenhang
zwischen Dependenzstrukturen und Konstituentenstrukturen und allgemein zwischen
Dependenz und Konstituenz herstellen:
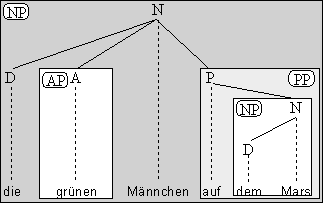
Abb. 4.17. Dependenz und Konstituenz
Betrachten wir nun folgenden englischen Satz
(4.46.) The automatic trucks from the factory carry coal up the sharp incline
Wenn wir die analytischen Operationen der Tilgung und Substitution auf die Konstituente
the automatic trucks from the factory dieses Satzes anwenden, erhalten wir
folgende Menge von Konstituenten:
|
(4.47.)
|
a. The automatic trucks from the factory
|
carry coal up the sharp incline
|
|
|
b. The automatic trucks
|
|
|
|
c. The trucks
|
|
|
|
d. Automatic trucks
|
|
|
|
e. Trucks
|
|
Diese Konstituenten (a – e) haben nicht nur gemeinsame distributionelle Eigenschaften,
sie teilen sich auch Eigenschaften der internen Struktur. Was sie u.a. gemeinsam
haben ist, daß sie ein Nomen als lexikalischen Kopf haben, d.h. sie erfüllen alle
die Definition einer N–Phrase (Nominalphrase):
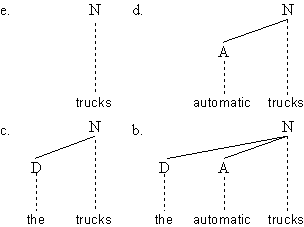
Abb. 4.18.
All diese Syntagmen können durch Anfügen der Kette from the factory (einer
PP) erweitert werden. Die strukturellen Möglichkeiten einer Nominalphrase lassen
sich wie folgt tabellarisch darstellen, wobei fakultative Elemente eingeklammert
sind:
|
NP
|
|
(D)
|
(AP)
|
N
|
(PP)
|
|
|
(Adv)
|
A
|
|
P
|
NP
|
|
|
|
|
|
|
(D)
|
N
|
Abb. 4.19.
In dem Satz the policeman stole a button ist die Teilkette the policeman
eine Nominalphrase. Wir können jetzt die Frage stellen, welche Syntagmen in der
Umgebung the policeman oder allgemeiner in der Umgebung NP vorkommen können.
Einige Möglichkeiten zeigt das folgende Beispiel:
|
(4.48.)
|
The policeman
|
a.
|
slept
|
|
|
|
b.
|
is quite bald
|
|
|
|
c.
|
stole a button
|
|
|
|
d.
|
gave his mother a cake
|
|
|
|
e.
|
sent for the doctor
|
|
|
|
f.
|
took the book from the shelf
|
Was diese Ketten gemeinsam haben ist, daß sie ein Verb als lexikalischen Kopf haben.
Sie sind Verbalphrasen (abgekürzt VP). (Die Kette quite bald ist eine Adjektivphrase
(AP) und besteht aus einem Gradadverb (Adv) das vom Adjektiv abhängt.)
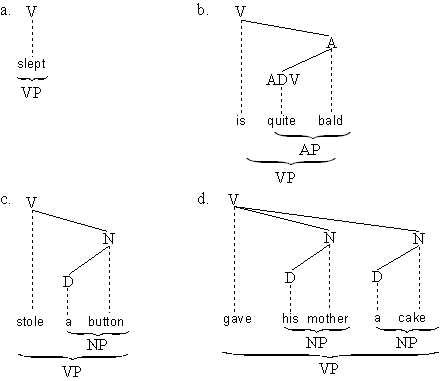
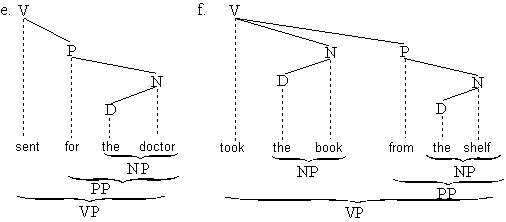
Abb. 4.20. Strukturen der Verbalphrase
Üblicherweise wird in der Dependenztheorie davon ausgegangen, daß die Subjekts-Nominalphrase
vom Hauptverb abhängig ist. Wir werden dieser Praxis hier nicht folgen. Wie schon
früher erwogen, werden wir davon ausgehen, daß die Beziehung zwischen der Subjekts-Nominalphrase
und dem Verb auf Interdependenz beruht. Ein einfacher Satz wie
(4.49.) The gardener planted a tree
wird wie folgt repräsentiert werden:
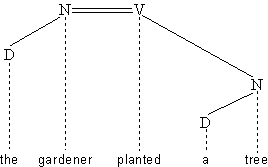
Abb. 4.21.
Die Subjekts-Nominalphrase (hier: the gardener) und die Verbalphrase (hier:
planted a tree) bilden zusammen einen Satz.
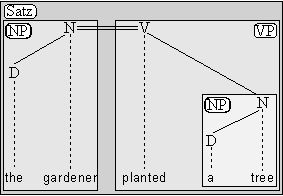
Abb. 4.22.
Definition 4.27. syntaktische Kategorie
Die Kategorie Satz (S) und alle X-Phrasen (XP), wobei X eine lexikalische Kategorie
ist, sind syntaktische Kategorien.
Definition 4.28. grammatische Kategorie
Lexikalische Kategorien and syntaktische Kategorien sind (primäre) Grammatische
Kategorien.
Die wichtigsten Kategorien sind in der folgenden Tabelle zusammengefaßt. Die Punkte
deuten an, daß eventuell weitere Kategorien angenommen werden müssen, um die syntaktische
Struktur natürlicher Sprachen adäquat beschreiben zu können.
|
|
Grammatische
Kategorien
|
Kategorialsymbol
|
|
Syntaktische
|
Satz
|
S
|
|
Kategorien
|
Nominalphrase
|
NP
|
|
|
Verbalphrase
|
VP
|
|
|
Adjektivphrase
|
AP
|
|
|
Präpositionalphrase
|
PP
|
|
|
|
|
|
Lexikalische
|
Determinator
|
D
|
|
Kategorien
|
Nomen
|
N
|
|
|
Verb
|
V
|
|
|
Adjektiv
|
A
|
|
|
Präposition
|
P
|
|
|
Konjunktion
|
K
|
|
|
|
|
|
NP:
|
a radioactive mineral, a splinter in my eye, all these very old ladies
|
|
VP:
|
painted the wall, swam across the channel, ran fast, stood
on his head ...
|
|
AP:
|
very old, bigger than a Cadillac, easy to please, conducive
to good health...
|
|
PP:
|
in the garden, under the table, across the channel ...
|
Phrasenstruktur-Grammatik (PSG)
Phrasenstruktur
Wir können zwei Grundmodelle der grammatischen Beschreibung unterscheiden, je nachdem,
welche Art grammatischer Relation als grundlegend betrachtet wird. Zur Auswahl stehen
Dependenz und Konstituenz. Die meisten der gegenwärtigen Grammatiktheorien verwenden
die Konstituenz als ihre Grundrelation. Wir haben jedoch bereits gesehen, daß zwischen
der Konstituentenstruktur und der Dependenzstruktur ein enger Zusammenhang besteht.
Beide erfassen wesentliche Aspekte der syntaktischen Struktur von Sätzen und es
wäre wünschenswert, eine Repräsentationsform zu finden, die beiden Aspekten Rechnung
trägt. Wir werden später zu dieser Frage zurückkehren. In den folgenden Abschnitten
werden wir ein geläufiges Grammatikmodell behandeln, das auf der Grundrelation der
Konstituenz aufbaut. Konstituenten oder Syntagmen werden im Englischen auch Phrases
genannt, was dem zur Diskussion stehenden Grammatiktyp seinen Namen gegeben hat:
Phrase Structure Grammar, ins Deutsche übernommen als Phrasenstruktur-Grammatik,
abgekürzt als PS-Grammatik bzw. PSG. Für den folgenden Satz
(4.50.) The radical change produced reflection upon other issues
kann die Konstituentenstruktur in Abb. 4. angenommen werden:
Mit den in den vorangehenden Abschnitten eingeführten Begriffen können Sätze nunmehr
unter Bezug auf die Konstituentenklassen oder grammatischen Kategorien analysiert
werden, welchen ihre Konstituenten angehören.
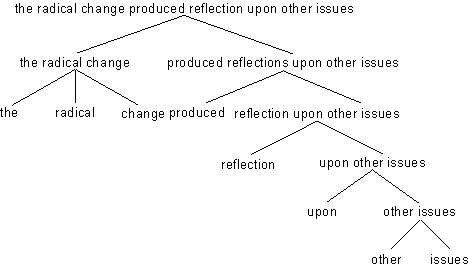
Abb. 4.23.
Alle Konstituenten in Abb. 4.23. gehören zu bestimmten Konstituentenklassen
(vgl. Abb. 4..) Zum Beispiel:
- The radical change ist eine Nominalphrase
- produced reflection upon other issues ist eine Verbalphrase
- reflection upon other issues ist eine Nominalphrase
- upon other issues ist eine Präpositionalphrase
- other issues ist eine Nominalphrase
Wir können dies weiter untermauern, indem wir die Dependenzstruktur jeder Konstituente
betrachten und die Definition der X-Phrase darauf anwenden:
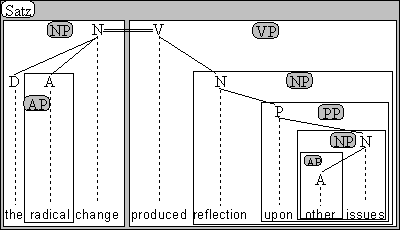
Abb. 4.24.
Wir können allgemein die Aussage, daß eine bestimmte Wortfolge Wk
ein Element einer bestimmten Kategorie Kat ist, in Form Kat(Wk)
ausdrücken. Zum Beispiel kann die Aussage, daß die Kette the radical change
eine Nominalphrase ist, durch NP(the radical change) repräsentiert
werden.
Auf diese Weise können wird die Mitgliedschaft der Konstituenten eines gegebenen
Satzes in grammatischen Kategorien darstellen.
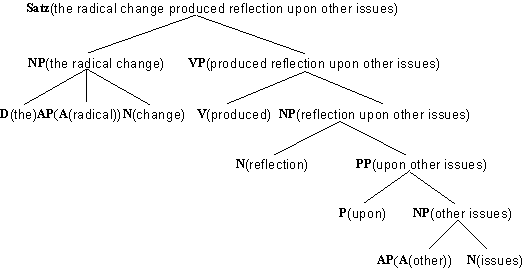
Abb. 4.25.
Die Verzweigungen in diesem Baum repräsentieren die Relation der Konstituenz: Ein
Baum wie
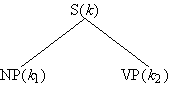
Abb. 4.26.
wobei k, k1, k2 Ketten sind, repräsentiert
eine Menge von Aussagen wie die folgenden:
- k ist ein Satz
- kl ist eine Nominalphrase
- k2 ist eine Verbalphrase
- kl ist eine unmittelbare Konstituente von k
- k2 ist eine unmittelbare Konstituente von k
- kl steht vor k2
- k = kl + k2 (i.e. k ist Verkettung
von kl und k2)
Phrasen-Struktur-Regeln
Es ist üblich, die Kategorialsymbole selbst als Kettenvariable fungieren zu lassen:
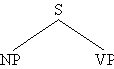
Abb. 4.27.
In dieser Konfiguration repräsentiert NP eine Kette mit den folgenden Eigenschaften:
- sie ist eine Nominalphrase;
- sie ist eine unmittelbare Konstituente einer weiteren Kette, die zur Kategorie S
gehört;
- sie steht unmittelbar vor einer Kette, die eine VP ist.
Mit diesen Begriffen kann die Konstituentenstruktur von Sätzen nunmehr unter Bezug
auf die syntaktischen Kategorien, welchen jede Konstituente angehört, repräsentiert
werden. Das wird in dem Beispiel Abb. 4.. gezeigt. Wie in den Dependenzdiagrammen
wird die ist-ein-Relation zwischen Wörtern und Wortklassen durch eine gestrichelte
Linie angezeigt.
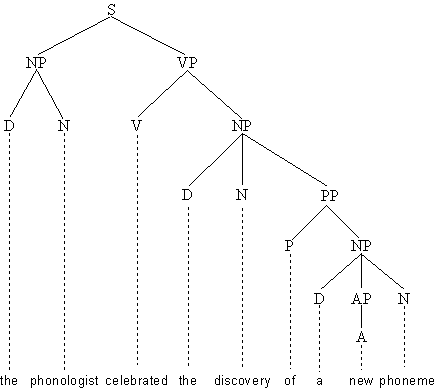
Abb. 4.28.
Was übrig bleibt, wenn wir die lexikalischen Elemente weglassen, ist eine Repräsentation
der Konstituentenstruktur nicht nur des Ausgangssatzes, sondern einer ganzen Klasse
von Sätzen, nämlich der Klasse von Sätzen, welche die gleiche Konstituentenstruktur
wie der Ausgangssatz haben. Auf der Grundlage von Verallgemeinerungen dieser Art
können wir jetzt Regeln formulieren, die bestimmen, wie Ketten, die Sätze ausdrücken,
aus Konstituenten aufgebaut sind, die zu bestimmten grammatischen Kategorien gehören.
Wir können beispielsweise die Verallgemeinerung treffen, daß eine Kette k
ein Satz ist, wenn sie aus zwei Teilketten kl und k2
besteht derart, daß k = kl+ k2, kl
zur Kategorie NP gehört und k2 zur Kategorie VP.
Wir werden dies wie folgt darstellen:
(4.51.) S → NP VP
Diese Regeln werden Konstituentenstruktur-Regeln (KS-Regeln) oder Phrasenstruktur-Regeln
(PS-Regeln) genannt:
Definition 4.29. Phrasenstruktur–Regel
Phrasenstruktur–Regeln sind Regeln, die die unmittelbaren Konstituenten von
Ketten und deren Zugehörigkeit zu grammatischen Kategorien festlegen. Ihre allgemeine
Form ist A → B, wobei A eine grammatische Kategorie (der Regelkopf) ist und
B ein Kette aus einer oder mehreren grammatisch Kategorien (der Regelkörper), oder
ein lexikalisches Element. Ist B ein lexikalisches Element, drückt A → B die
ist-ein-Relation aus (B ist ein A).
Definition 4.30. Phrasenstruktur-Grammatik (PSG)
Die Menge der Phrasenstruktur-Regeln einer Sprache ist eine Phrasenstruktur-Grammatik
dieser Sprache.
Beispiel für eine einfache Phrasenstrukturgrammatik (Englisch):
Definition 4.31. Strukturbeschreibung
Die Strukturbeschreibung eines Satzes ist eine Spezifikation seiner Konstituentenstruktur
unter Angabe der Zugehörigkeit zu grammatischen Kategorien.
Definition 4.32. generative Grammatik
Die Menge der Regeln, die explizit festlegen, welche Wortketten Sätze einer Sprache
sind und gleichzeitig jedem Satz eine Strukturbeschreibung zuweisen, ist eine generative
Grammatik dieser Sprache.
Definition 4.33. Phrasenmarker
Jede Repräsentation, welche die Konstituentenstruktur eines Satzes und die Mitgliedschaft
jeder Konstituente in grammatischen Kategorien darstellt, ist ein Phrasenmarker
(PM).
Die üblichen Formen eines Phrasenmarkers sind indizierte Klammern oder indizierte
Bäume, die in verschiedener Gestalt auftreten. Zum Beispiel kann eine Regel wie
S &rarrM NP VP als Anweisung folgender Art aufgefaßt werden: "Gegeben sei das
Kategorialsymbol S in einer Kette von Kategorialsymbolen. Ersetze S durch den Ausdruck
[NP VP]S". Mit den oben aufgeführten PS-Regeln können wir beispielsweise
die folgende schrittweise Ableitung konstruieren:
1. S
2. [NP VP]S
3. [[D N]NP VP]S
4. [[D N]NP [V NP]VP]S
5. [[D N]NP [V [D N]NP]VP]S
6. [[[the]D N]NP [V [D N]NP]VP]S
7. [[[the]D [boy]N]NP [V [D N]NP]VP]S
8. [[[the]D [boy]N]NP [[petted]V [D
N]NP]VP]S
9. [[[the]D [boy]N]NP [[petted]V [[the]D
N]NP]VP]S
10. [[[the]D [boy]N]NP [[petted]V [[the]D
[dog]N]NP]VP]S
Ein Baum besteht aus einer Menge von Knoten, die durch Kategorialsymbole (S, NP,
VP etc.) bezeichnet werden, und einer Menge von Kanten, welche die Knoten verbinden
und bestimmte Relationen zwischen Kategorien repräsentieren. Die Regel S → NP
VP kann als folgende Anweisung interpretiert werden: "Gegeben sei der
Knoten S in einem Baum: konstruiere einen Teilbaum durch Anhängen der Knoten NP
und VP in dieser Reihenfolge," d.h.

Gleichzeitig definiert die Regel Relationen zwischen den Knoten:
Definition 4.34. unmittelbar dominieren
Gegeben sei eine Regel
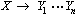 , wobei
X und
, wobei
X und
 Kategorien sind. Dann gilt: X dominiert unmittelbar jedes
. Die Regel
Kategorien sind. Dann gilt: X dominiert unmittelbar jedes
. Die Regel
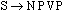 spezifiziert, daß S in dem entsprechenden Phrasenmarker unmittelbar NP und
VP dominiert.
spezifiziert, daß S in dem entsprechenden Phrasenmarker unmittelbar NP und
VP dominiert.
Definition 4.35. dominieren
Dominieren ist eine binäre Relation zwischen zwei Kategorien X und Y mit folgenden
Eigenschaften:
- X dominiert Y, wenn X das Y unmittelbar dominiert.
- X dominiert Y, wenn es ein Z gibt derart, daß X unmittelbar Z dominiert, und Z Y
dominiert.
Zum Beispiel dominiert in dem folgenden Baum S unmittelbar die Knoten NP1
und VP; es dominiert den Knoten N2, weil es einen Weg S → VP →
NP2 → N2 gibt, wo jedes nebeneinanderstehende Paar in
der "dominiert unmittelbar" Relation steht.
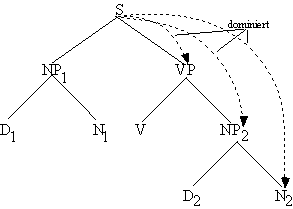
Abb. 4.30.
Definition 4.36. Präzedenz
Eine PS-Regel der Form A → B C sagt auch aus, daß in der Kette A
die Teilkette B der Teilkette C vorausgeht.
Zur Identifizierung bestimmter Positionen in einem Baum werden häufig Ausdrücke
aus einer Stammbaummetapher verwendet (Mutter, Tochter, Schwester, etc.):
Definition 4.37. Mutter
Ein Knoten ist die Mutter aller Knoten, die er direkt dominiert.
In unserem Beispielbaum ist S die Mutter der Knoten NP1 und VP,
VP ist die Mutter von V und NP2. (Statt Mutter wird auch Vater
verwendet).
Definition 4.38. Tochter
Knoten, die direkt von einem anderen Knoten dominiert werden, sind Töchter dieses
Knotens. Die Tochterrelation ist die Umkehrung der Mutterrelation, d.h. es gilt
für zwei beliebige Knoten X und Y: wenn Mutter(X, Y ) dann Tochter(Y, X)
Die Töchter von S sind NP1 und VP.
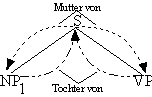
Abb. 4.31. Mütter und Töchter
Definition 4.39. Vorfahr
Ein Knoten ist Vorfahr aller Knoten, die er dominiert.
Zum Beispiel ist VP der Vorfahr der Knoten V, NP2,
D2 und N2.
Definition 4.40. Abkömmling
Knoten, die von einem anderen Knoten dominiert werden, sind Abkömmlinge diese Knotens.
Die Abkömmling-Beziehung ist die Umkehrung der Vorfahr-Relation, d.h. es gilt für
zwei beliebige Knoten X und Y: wenn Vorfahr(X, Y ) dann Abkömmling(Y, X).
Definition 4.41. Schwester
Knoten, die Töchter des gleichen Knotens (der gleichen Mutter) sind, sind Schwestern
von einander (sind Geschwister).
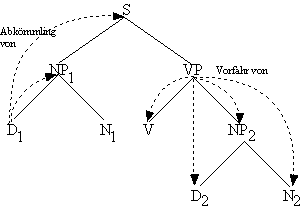
Abb. 4.32. Vorfahren und Abkömmlinge
Es gibt gewisse Abkürzungskonventionen zur Vereinfachung der Formulierung von PS-Regeln.
Geschweifte Klammern ‘{’ ‘}’ zeigen Alternativen an. Mehrere
Regeln mit dem gleichen Regelkopf, aber verschiedenen Regelkörpern, können durch
die Verwendung von geschweiften Klammern zusammengefaßt werden:
(4.52.)
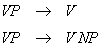 kann zu
kann zu
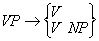 zusammengefaßt werden.
zusammengefaßt werden.
Optionale (fakultative) Elemente können eingeklammert werden, so daß sich die obige
Regel weiter zur folgenden Fassung vereinfache läßt:
(4.53.) VP → V(NP)
Es folgt eine vereinfachte PS-Grammatik des Englischen. Wir unterscheiden zwischen
syntaktischen und lexikalischen Regeln:
Syntaktische Regeln:
(1) S → NP VP
(2) VP → V(NP)(PP)
(3) NP → (D)(AP)N(PP)
(4) PP → P NP
(5) AP → (ADV)A
Lexikalische Regeln:
(6) D → a,the
(7) N → boy, girl, student, professor...
(8) V → slept, ran, called, wrote
(9) A → young,old,nice,pretty
(10) P → in, under, over, across
(11) ADV → very,extremely,terribly...
Eine Phrasenstrukturregel wie
S → NP VP
kann auf unterschiedliche Weise interpretiert werden:
1. Symbole die links des Pfeils stehen dominieren unmittelbar Symbole rechts des
Pfeils, d.h. S dominiert unmittelbar NP und VP. Die Reihenfolge der Symbole
auf der rechten Seite des Pfeils stellt die Präzedenzrelation (x vor y) dar. Symbole
rechts des Pfeils dominieren vollständig die Symbolfolge auf der rechten Seite.
Die Umkehrung der Relation "dominiert vollständig" ist die Relation "ist
ein". S dominiert vollständig die Folge NP + VP, die Folge NP + VP
ist ein S.
2. Besteht aus: Eine Kette der Kategorie links des Pfeils besteht aus (hat als unmittelbare
Konstituenten) Teilketten der Kategorien rechts des Pfeils, in der angegebenen Reihenfolge.
Eine Kette k, die ein S ist, besteht aus zwei Teilketten ~l und k2 derart, daß gilt
kl ist ein NP und k2 ist ein VP, und k = kl + k2, wobei + die
Operation der Verkettung symbolisiert.
3. Mengentheoretische Interpretation: Die Menge der Elemente der Kategorie links
des Pfeils ist definiert durch das kartesische Produkt aus den Mengen der Elemente
der Kategorien rechts des Pfeils: S = NP x VP. Sei beispielsweise NP={Hans,
Maria} und VP={singt, lacht}, dann ist S = NP x VP={(Hans, singt), (Hans, lacht),
(Maria, singt), (Maria, lacht)}.
4. Konstruktionsanweisungen
a. Gegeben sei das Symbol links des Pfeils; ersetze es durch die Symbolkette rechts
des Pfeils. Z.B. sei S gegeben, dann ersetze S durch NP VP.
b. Etwas informativer als (a): ersetze S durch den Klammerausdruck [NP VP]s,
wodurch Strukturbeschreibungen entstehen, welche die "ist ein"-Relation
repräsentieren.
c. Gegeben sei das Symbol links des Pfeils als Knoten in einem Baum. Verbinde den
Knoten mit den Knoten rechts des Pfeils in der angegebenen Reihenfolge. Gegeben
sei S, konstruiere S
NP VP
Anderes ausgedrückt, durch eine PS-Regel wird ein wohlgeformter Teilbaum definiert.
Dies ist natürliche nur eine "Spielzeuggrammatik". Eine realistische Grammatik
wird sehr viel mehr Regeln enthalten und sehr viel komplexere Strukturen erfassen
müssen, als bisher besprochen wurden. Bevor wir unsere Analyse englischer Sätze
fortsetzen, wollen wir einige weitere Beispiele diskutieren.
Erweiterungen der Phrasenstrukturgrammatik
Die Grammatik am Ende des vorherigen Abschnittes ist natürlich nur eine "Spielzeuggrammatik".
Eine realistische Grammatik wird aus sehr viel mehr Regeln bestehen und sehr viel
komplexere Strukturen beschreiben müssen, als die bisher besprochenen. Insbesondere
fehlen Regeln für die Beschreibung zusammengesetzter Sätze. Bevor wir uns mit einigen
Erweiterungen dieser Grammatik befassen, wollen wir einige einfache Beispiele diskutieren.
Gegeben seien die folgenden Sätze:
|
(4.54.)
|
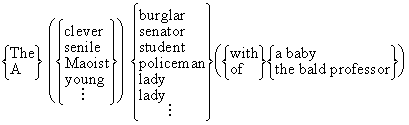
(a) The clever burglar bribed a policeman
|
|
|
(b) The senile senator wooed a young lady with a baby
|
|
|
(c) A Maoist student stole the wig of the bald professor
|
Es soll eine PS-Grammatik erstellt werden, welche diese alle diese Sätze beschreibt.
Diese Sätze sind auf einer allgemeinen Strukturebene nach dem gleichen Muster gebaut.
Dies wird deutlich, wenn wir durch Anwendung der Weglaßprobe ihre Minimalstruktur
ermitteln.
|
(4.55.)
|
(a) The clever burglar bribed a policeman
|
|
|
(b) The senile senator wooed a young lady
with a baby
|
|
|
(c) A Maoist student stole the wig of the bald professor
|
Wir können die Sätze wie folgt gruppieren:
(4.56.)

Diesen Fakten wird zunächst durch folgende Phrasenstrukturregeln Rechnung getragen:
R1: S → NP VP
R2: VP → V NP
Was noch darzustellen bleibt, ist die interne Struktur der Nominalphrasen:
(4.57.)

Weggelassen werden können die Adjektive clever, senile, Maoist, young, bald
und die Wortgruppen with a baby und of the bald professor. Letztere
setzen sich aus einer Präposition und einer Nominalphrase zusammen:
(4.58.)
Dafür brauchen wir also folgende Regeln:
R3: NP → D (AP) N (PP)
R4: PP → P NP
R5: AP → A
Die übrigen Regeln sind Regeln des Lexikons.
Gegeben sei die Grammatik aus dem vorhergehenden Beispiel. Zeigen Sie, daß der nachfolgende
Satz ebenfalls zur Sprache gehört, die durch diese Grammatik definiert wird:
(4.59.) The young student with the wig of the Maoist professor bribed the senile
policeman

Rekursive Kategorien
Betrachten wir die beiden folgenden Regeln
(4.60.) (1) NP → D N (PP)
(2) PP → P NP
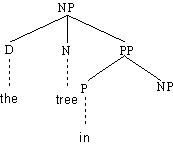
Sie erklären Syntagmen wie [[the]D [tree]N [in the garden]PP
]NP. Es handelt sich dabei um eine Nominalphrase, welche eine Präpositionalphrase
([in the garden]PP) enthält. Gemäß Regel (2) jedoch besteht eine Präpositionalphrase
ihrerseits aus eine Präposition und einer Nominalphrase. Ausgehend von einem Teilbaum
wie in Abb. 4.34. wird die Regel (1) erneut anwendbar, wobei möglicherweise
eine weitere PP als Teil der Nominalphrase eingeführt wird.
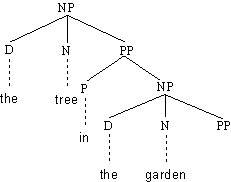
Abb. 4.34.
Es entsteht so ein Zyklus: Regel (1) kann eine Präpositionalphrase einführen, wodurch
Regel (2) erneut anwendbar wird, was uns zur Regel (1) zurückführt, und so fort.
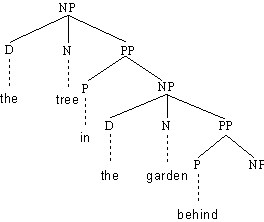
Abb. 4.35.
Der Zyklus endet, wenn die optionale Präpositionalphrase in der NP-Regel nicht gewählt
wird:
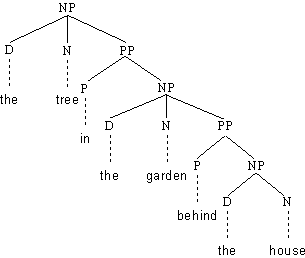
Abb. 4.36.
Kategorien, welche dies Eigenschaft haben, d.h. die in Konfigurationen vorkommen
wie
Abb. 4.37.
sind rekursive Kategorien. In unserem Beispiel sind NP und PP rekursive Kategorien.
Rekursivität erklärt die Nicht-Endlichkeit natürlicher Sprachen. Weil Nominalphrasen
potentiell nicht abgeschlossen sind, können auf diese Weise unbegrenzt viele davon
konstruiert werden.
Ähnliches gilt für Relativsätze wie: The dog that chased the cat... Wie Präpositionalphrasen
sind Relativsätze Konstituenten von Nominalphrasen, d.h. die Phrasenstruktur des
zur Diskussion stehenden Beispiels sieht ungefähr wie folgt aus:
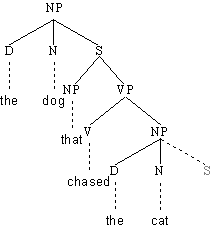
Abb. 4.38.
Zur Erklärung solcher Strukturen benötigen wir eine NP-Regel wie
(4.61.)
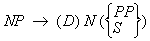 ,
,
die besagt, daß der Kopf einer Nominalphrase fakultativ entweder durch eine Präpositionalphrase
oder durch einen ganzen Satz modifiziert werden kann. Nun enthalten Sätze offensichtlich
ihrerseits Nominalphrasen in unterschiedlichen Positionen, so daß die Kategorie
S mehrfach auftreten kann. Mit anderen Worten: die Kategorie S ist eine rekursive
Kategorie.
(4.62.) The dog [that chased the cat [that chased the rat [that chased the mouse
[that stole the cheese]]]]... collapsed.
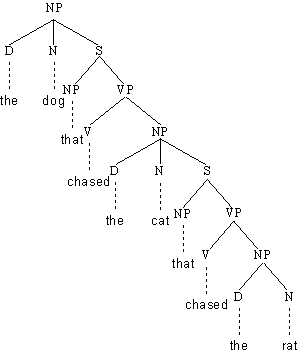
Abb. 4.39.
Subkategorisierung
Gegeben sei die folgende stark vereinfachte PS-Grammatik des Englischen:
SYNTAKTISCHE REGELN:
|
(4.63.)
|
(1) S → NP VP
|
|
|
(2) VP → V (NP)(PP)
|
|
|
(3) NP → (D)(AP) N (PP)
|
|
|
(4) AP → (ADV) A
|
|
|
(5) PP → P NP
|
LEXIKALISCHE REGELN:
|
(4.63.)
|
(6) D → the,...
|
|
|
(7) N → boy, girl, student, professor, sincerity, book ...
|
|
|
(8) V → slept, ran, called, wrote, admired, frightened,...
|
|
|
(9) A → young, old, nice, pretty,...
|
|
|
(10) ADV → very, extremely, terribly ...
|
|
|
(11) P → to, about, in, into, against ...
|
Dabei handelt es sich um ein erstes Modell der internalisierten Grammatik eines
kompetenten Sprechers des Englischen, welche sein sprachliches Wissen bestimmt.
Dieses Modell ist in mehrfacher Hinsicht inadäquat. Erstens prognostiziert es Sätze,
die bezüglich der Grammatik des Englischen ungrammatisch sind:
|
(4.64.)
|
(1) *the boy ran the professor
|
|
|
(2) *the student admired the sincerity
|
|
|
(3) *the sincerity admired the student
|
|
|
(4) *the book frightened
|
|
|
(5) *the student slept about the book
|
|
|
(6) *the book called the professor to the girl
|
Zweitens werden Ketten, die zweifelsfrei Sätze des Englischen sind, nicht erfaßt,
selbst wenn wir annehmen, daß die darin vorkommenden Wörter in den lexikalischen
Regeln enthalten sind.
|
(4.64.)
|
(7) the student bought the book the professor wrote
|
|
|
(8) the professor was completely in the wrong
|
|
|
(9) sincerity frightened the boy
|
|
|
(10) they elected John president
|
Folglich müssen wir unser Modell modifizieren und ein verbessertes Modell konstruieren,
welches die ungrammatischen Sätze nicht zuläßt aber die grammatischen in (4.64)(7)
– (10) erfaßt. Dazu müssen wir zunächst herausfinden, was an den abweichenden
Sätzen eigentlich falsch ist. Wie können wir den Fehler beseitigen?
|
(4.65.)
|
(1) (a) the boy ran (to the professor)
|
|
|
(2) (a) the student admired sincerity (the sincerity of the professor)
|
|
|
(3) (a) the professor admired the student
|
|
|
(3) (b) the student admired sincerity
|
|
|
(4) (a) the book frightened the student
|
|
|
(5) (a) the student talked about the book
|
|
|
(6) (a) the student called the professor
|
|
|
(6) (b) the professor gave the book to the girl
|
(4.)(1) ist deshalb ungrammatisch, weil das Verb run (im Gegensatz zu saw)
im allgemeinen kein direktes Objekt zuläßt; es ist ein intransitives Verb. Wir erhalten
korrekte Sätze, indem wir entweder the professor ganz weglassen oder durch
die Präposition to erweitern.
(4.)(2) ist abweichend, weil sincerity ein Nomen ist, das bei unspezifischer
(generischer) Referenz ohne Artikel steht (im Gegensatz zum spezifischen the sincerity
of the professor). Das Verb admire in (4.)(3) hinwiederum legt dem
Subjekt Beschränkungen auf: es muß als Kopf ein Nomen haben, das ein menschliches
Lebewesen bezeichnet.
Es gibt in grammatischen Ausdrücken offensichtlich Abhängigkeiten, deren Beschreibung
es erforderlich macht, innerhalb der verschiedenen lexikalischen Kategorien Subkategorien
(Unterkategorien) zu unterscheiden, je nach der syntaktischen Umgebung, in der sie
vorkommen können.
Definition 4.42. Subkategorisierung
Subkategorisierung nennt man die Untergliederung der lexikalischen Kategorien (Nomen,
Verb, etc.) in syntaktisch-semantisch motivierte Subkategorien um bestimmten Abhängigkeitsbeziehungen
im Satz Rechnung zu tragen.
Wenn wir zunächst auf die Verben konzentrieren, müssen wir Verben, die keine Ergänzung
(Komplement) zulassen, von solchen unterscheiden, die Ergänzungen zulassen oder
gar fordern, und bei letzteren verschiedene Unterarten. So verlangt admire
eine Nominalphrase als Ergänzung, give eine Nominalphrase und eine Präpositionalphrase
(oder zwei Nominalphrasen wie in the professor gave the girl a book). Verben
ohne Komplemente heißen intransitiv, solche mit einer NP als Komplement transitiv.
Man bezeichnet die Eigenschaft von Wörtern, bestimmte Ergänzungen zuzulassen bzw.
zu verlangen als ihre Wertigkeit oder Valenz.
Definition 4.43. Valenz
Valenz ist ein aus der Chemie entlehnter Begriff und bezeichnet die Fähigkeit eines
Lexems (z.B. eines Verbs, Adjektivs, Nomens), seine syntaktischen Umgebungen im
Satz vorzustrukturieren, indem es anderen Konstituenten Bedingungen bezüglich ihrer
Anzahl und ihrer grammatischen Eigenschaften (syntaktische Kategorie, sekundäre
grammatische Katgorien wie Genus, Kasus etc.) auferlegt.
Unsere VP-Regel muß also etwa wie folgt verändert werden:
(4.) (2)(a) VP →
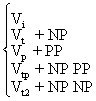
(Vi = intransitives Verb, Vt = transitives Verb, Vp
= Verb mit Präpositionalobjekt, Vtp = transitives Verb mit Präpositionalobjekt,
Vt2 = ditransitives Verb)
(4.) (8) (a) Vi → ran, jumped, cried, called, talked ...
(b) Vt → called, wrote, frightened, kicked, broke ...
(c) Vp → talked, lived, depended, ...
(d) Vtp → gave, sent, ...
(e) Vt2 → taught, gave, ...
Bei der Ableitung eines Satzes muß zur Erzeugung einer Verbalphrase eine der Alternativen
aus Regel (4.)(2)(a) gewählt werden, z.B. VP → V NP
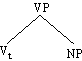
Abb. 4.40.
Damit ist automatisch die Wahl des Verbs eingeschränkt auf Regel (4.)(8)(b), z.B.
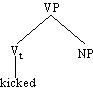
Abb. 4.41.
Die Subkategorisierung von lexikalischen Kategorien nach der unmittelbaren syntaktischen
Umgebung, in der sie vorkommen können, wird strikte Subkategorisierung genannt.
Definition 4.44. strikte Subkategorisierung
Strikte Subkategorisierung bedeutet strikt lokale, d.h. auf die Ko-Konstituenten
der fraglichen Kategorie innerhalb einer Konstituente beschränkte, Subkategorisierung.
Die strikte Subkategorisierung des Verbs berücksichtigt also nur den syntaktischen
Kontext innerhalb der Verbalphrase.
Ausgehend vom Englischen hat sich die aus der Sicht des Deutschen unschöne Redeweise
eingebürgert, daß eine lexikalische Kategorie seinen lokalen Kontext subkategorisiert,
was eigentlich unsinnig ist. Man sagt also z.B. "Vt subkategorisiert
eine NP", oder "Vp subkategorisiert eine PP", und "Vtp
subkategoriseirt eine NP und eine PP" etc.
Die oben in (2)(a) vorgeschlagene Lösung hat allerdings einen gravierenden Schönheitsfehler.
Das Problem ist, daß wir nun nicht mehr ausdrücken können, daß alle als Vi,
Vt, Vp etc. klasssifizierten Wörter Verben sind. Wie haben
zwar jetzt intransitive, transitive, ditransitive etc. Verben, aber wir haben keine
Verben mehr und können folglich keine Aussagen mehr über die Klasse Verb als Ganzes
machen.
Zur Lösung dieses Problemes gibt es verschiedene Möglichkeiten:
1. Kontextsensitive Regeln:
Die bisher von uns verwendeten Phrasenstruktur-Regeln waren von der Form A →
B, d.h. ein links vom Pfeil stehendes Symbol (hier A) konnte unabhängig von dem
syntaktischen Kontext, in dem es steht, durch den Ausdruck rechts des Pfeiles (hier
B) spezifiziert werden. Solche Regeln heißen kontextfrei.
Definition 4.45. kontextfreie Regel
Eine kontextfreie Phrasenstrukturregel hat die Form A → B, d.h. ein Symbol
A kann ohne Berücksichtigung des Kontextes, in dem es steht, durch ein Symbol oder
eine Symbolfolge B spezifiziert (ersetzt, expandiert etc.) werden.
Definition 4.46. kontextfreie Grammatik
Eine Grammatik, die nur kontextfreie Regeln enthält, heißt kontextfrei.
Eine Regel, die Bezug nimmt auf den unmittelbaren syntaktischen Kontext, heißt kontextsensitiv
(auch: kontextabhängig oder kontextbeschränkt).
Definition 4.47. kontextsensitive Regel
Eine kontextsensitive (kontextabhängige, oder kontextbeschränkte) Regel hat die
Form XAY → XBY, d.h. ein Symbol A kann durch ein Symbol oder eine
Symbolfolge B spezifiziert werden, wenn eine Symbolfolge X vorausgeht und eine Symbolfolge
Y folgt. X und Y können auch leer sein. Wenn sowohl X als auch Y leer sind, geht
die kontextsensitive in eine kontextfreie Regel über. Statt XAY → XBY schreibt
man auch: A → B / X — Y (lies: A wird zu B in der Umgebung X —
Y).
Beispiel: In norddeutschen Dialekten des Deutschen wird der Laut [g] (wie in Gabe)
als stimmhafter Reibelaut [ɣ] gesprochen, wenn er zwischen zwei Vokalen steht, z.B.
Säge [zɛ:gə] → [zɛ:ɣə]. Wenn wir Vokale durch das Symbol V bezeichnen,
gilt also die kontextsensitive Regel:
(4.66.) (a) VgV → VɣV, bzw.
(b) g → ɣ / V — V
Definition 4.48. kontextsensitive Grammatik
Eine Grammatik, die kontextsensitive Regeln enthält, heißt kontextsensitiv.
Wir können unser Problem mit der Verbalphrase dadurch lösen, daß wir zunächst den
Kopf V der VP durch eine kontextfreie Regel wie (4.)(2)(b) einführen, und dann dieses
V in Abhängigkeit vom jeweiligen Kontext weiter als Vi, Vt
etc. spezifizieren.
(4.) (2)(b) VP → V(NP)( )
)
(4.) (2)(c) V →
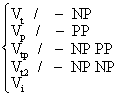
Wird durch Regel (4.)(2)(b) beispielsweise die Teilstruktur 1.42 abgeleitet, dann
bestimmt die kontextsensitive Regel (4.)(2)(c), daß das V nur zu Vt weiterentwickelt
werden kann:
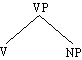
Abb. 4.42.
Abb. 4.43.
2. Subkategorisierung durch syntaktische
Merkmale:
Kontextsensitive Grammatiken sind sehr komplex, sowohl in ihrem Aufbau als auch
in ihrer Anwendung bei der Generierung und Analyse von Sätzen. Es ist daher ein
erstrebenswertes Ziel, eine Sprache durch eine weitgehend kontextfreie Grammatik
beschreiben zu können. Wir wollen daher versuchen, die angesprochenen Probleme mit
kontextfreien Mitteln zu lösen.
Eine neuerdings vielfach gewählte Möglichkeit, die Ausdrucksfähigkeit von Phrasenstrukturgrammatiken
zu erhöhen, besteht darin, die grammatischen Kategorien nicht als atomare, nicht
weiter analysierbare Entitäten zu betrachten, sondern als Bündel von Merkmalen.
In den oben aufgeführten Regeln sind Symbole wie V und Vt atomar und
nicht weiter analysierbar, und daß Vt eine Subkategorie von V ist ergibt
sich eigentlich nur durch die Regeln, in welchen beide vorkommen, z.B. V →
Vt / — NP.
Die Verwendung von Merkmalen im intendierten Sinne ist in der Linguistik nichts
neues. Merkmale spielen beispielsweise in der Phonologie schon seit langem eine
wichtige Rolle. Allgemein lassen sich Merkmale wie folgt definieren:
Definition 4.49. Merkmal
Ein Merkmal ist eine Zuordnung von einem Attribut und einem Wert (oder Ausprägung)
aus einem gegebenen Wertevorrat.
In diesem allgemeinen Sinne könnte z.B. "lexikalische Kategorie" als Attribut
aufgefaßt werden mit dem Wertevorrat {Nomen, Verb, Adjektiv, Präposition etc.}.
Wie wir im Kapitel zur Morphologie noch ausführlicher sehen werden, unterscheidet
man verschiedene "sekundäre" grammatische Kategorien wie Genus, Numerus,
Kasus, die ebenfalls Attribute in diesem Sinne sind. Das Attribut Genus z.B. hat
als "Merkmalsausprägungen" die Werte {Maskulinum, Femininum, Neutrum},
das Attribut Numerus die Werte {Singular, Plural}.
Eine Wortform wie Kindern in dem Ausdruck helft den armen Kindern
hat z.B. folgende partielle Merkmalstruktur:
|
Attribut
|
Wert
|
|
Kategorie
|
Nomen
|
|
Genus
|
Neutrum
|
|
Numerus
|
Plural
|
|
Kasus
|
Dativ
|
Tab. 4.1.
Merkmale werden üblicherweise in eckige Klammern gesetzt, z.B. [Genus Neutrum],
[Person 3]. Das Merkmalsbündel in Tab. 4.1 sieht dann wie folgt
aus:
 .
.
Von besonderem Interesse sind nun Merkmale, die nur zwei Merkmalsausprägungen haben,
sog. binäre Merkmale. Das gilt beispielsweise im Deutschen für das Attribut Numerus.
In einem solchen Fall wird häufig als Attribut einer der Merkmalswerte genommen
und als Merkmalsausprägung + oder -, wobei meist der
Wert vor das Attribut gestellt wird. Statt [Numerus Plural] schreibt
man also [+Plural], und statt [Numerus Singular] entsprechend
[−Plural]. Es handelt sich jedoch nur um Notationsvarianten des allgemeinen
Merkmalsbegriffs.
Häufig werden auch nicht-binäre Merkmale binär dargestellt. Dies gilt beispielsweise
für die kategorialen Merkmale:
Definition 4.50. kategoriales Merkmal
Kategoriale Merkmale kennzeichnen die Zugehörigkeit sprachlicher Einheiten zu grammatischen
Kategorien wie z.B. Nomen oder Verb. Anstelle von [Kategorie Nomen]
schreibt man meistens [+Nomen] bzw. kurz [+N]. Analog: [+V] für [Kategorie Verb]
bzw. [+A] für [Kategorie Adjektiv], etc.
Ist K eine lexikalische Kategorie, gilt allgemein:
(4.67.) K → [+K].
3. Kontextfreie Subkategorisierung
Wir haben am Beispiel von sincerity bereits gesehen, daß auch Nomina hinsichtlich
ihres grammatischen Verhaltens subkategorisiert werden müssen. Man vergleiche dazu
noch folgende Beispiele:
(4.68.)

Zunächst muß zwischen Eigennamen (engl. proper noun, z.B. John) und
Gattungsnamen oder Appellativum (engl. common noun, z.B. bottle, furniture,
cake, dt. Mann, Frau, Haus) unterschieden werden. Appellativa bezeichnen
eine ganze Gattung gleichgearteter Dinge und zugleich jedes einzelne Wesen oder
Ding dieser Gattung. Es handelt sich offenbar um ein binäres Merkmal und wir können
Gattungsnamen mit [+Appellativum] und Eigennamen mit [-Appellativum]
kennzeichnen. Es gilt also, daß eine Kategorie mit dem kategorialen Merkmal [+Nomen]
zusätzlich entweder das Merkmal [+Appellativum] oder [-Appellativum]
aufweist. Dies kann durch eine Regel der folgenden Art ausgedrückt werden:
(4.69.) (a) [+Nomen] → [±Appellativum]
dies ist eine konventionelle Abkürzunge für
(b) [+Nomen] →

Man nennt eine derartige Regel eine kontextfreie Subkategorisierungsregel.
Für das Englische gilt, daß Eigennamen ([−Appellativum]) nicht mit einem Artikel
[(b)–(d)] und nicht im Plural [(e)] verwendet werden können.
Die Appellativa können weiterhin unterteilt werden in Nomina, die wohlunterschiedene
Individuen bezeichnen (Individuativa, z.B. bottle, table, person, dt. Tisch,
Stuhl, Mann) und solche, für die das nicht zutrifft. Nach dem Englischen
wollen wir dafür das Merkmal zählbar (engl. count) einführen. Quer dazu gibt
es die weitere Unterscheidung zwischen Konkreta (Substantive, mit denen etwas Gegenständliches
bezeichnet wird, z.B. Mensch, Mann, Frau, Kind, Fisch, Blume, Haus, Tisch
etc.) und Abstrakta (Substantive, mit denen etwas Nichtgegenständliches, etwas Gedachtes
bezeichnet wird). Abstrakte bezeichnen z.B.
|
Menschliche Vorstellungen:
|
Geist, Seele;
|
|
Handlungen:
|
Schlag, Wurf, Korrektur;
|
|
Vorgänge:
|
Leben, Sterben, Schwimmen, Schlaf;
|
|
Zustände:
|
Friede, Ruhe, Angst, Liebe, Alter;
|
|
Eigenschaften:
|
Würde, Verstand, Ehrlichkeit;
|
|
Verhältnisse oder Beziehungen:
|
Ehe, Freundschaft, Nähe;
|
|
Wissenschaften, Künste:
|
Biologie, Mathematik, Linguistik;
|
|
Maß- und Zeitbegriffe:
|
Meter, Watt, Gramm; Jahr, Stunde, Mai).
|
Wir können dies in einer Regel folgendermaßen zusammenfassen, wobei die Werte '+'
bzw. '-' jeweils unabhängig voneinander gewählt
werden können.
(4.70.) [+Appellativum] → [±Zählbar, ±Konkret]
Diese Regel führt also zu vier verschiedenen Merkmalsbündeln:
[+Appellativum, + Zählbar, + Konkret] (Baum, Tisch, Hund, Ring),
[+Appellativum, + Zählbar, −Konkret] (Leidenschaft, Gedanke, Verbrechen),
[+Appellativum, −Zählbar, +Konkret] (Wasser, Sand, Mörtel),
[+Appellativum, −Zählbar, −Konkret] (Güte, Sanftmut, Liebe).
Nicht-zählbare Nomina können noch nach Kollektivbezeichnungen (Kollektiva: police,
group, people etc.) und Stoffbezeichnungen (water, cake, gold, wine,
dt. Wasser, Leder, Holz, Fleisch etc.) unterschieden werden.
Bei den Konkreta kann zwischen Nomina, die höhere Lebewesen bezeichnen, und anderen
unterschieden werden (Merkmal [±Belebt]). Gleiches gilt auch für Eigennamen:
|
(4.71.)
|
(a) [+Konrekt] [±Belebt]
|
|
|
(b) [-Appellativum] [±Belebt]
|
Bei den Nomina mit dem Merkmal [+Belebt] kann weiterhin zwischen menschlichen und
nichtmenschlichen Lebewesen differenziert werden.
(4.72.) [+Belebt] → [±Menschlich].
Das folgende Diagramm zeigt die schrittweise Ableitung eines Merkmalbündels nach
den obigen Regeln:
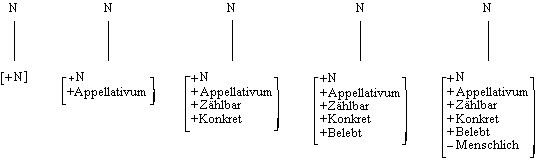
Abb. 4.44.
Im Lexikon müssen die Wörter entsprechend durch Merkmalsbündel charakterisiert sein.
[+N, +Appellativum, +Zählbar, + Konkret, +Belebt, -Menschlich]: Hund, Katze, Kuh,
Pferd, ...
Ein Wort kann dann in einer syntaktischen Struktur als terminale Konstituente verwendet
werden, wenn seine Merkmalsspezifikation von der des entsprechenden Knotens im Baum
nicht verschieden ist. Zwei Merkmalsbündel sind dann voneinander verschieden,
wenn es wenigstens ein gemeinsames Merkmal mit gegensätzlicher Spezifikation gibt.
Beispiele: [+Belebt, –Menschlich] ist nicht verschieden von [+Konkret]
[+Konkret, +Zählbar] ist verschieden von [–Belebt, –Zählbar]
4. Strikte
Subkategorisierung durch Merkmale
Unter der Annahme, daß grammatische Katgorien nicht atomar sind, sondern aus Merkmalskomplexen
bestehen, können wir auch das Problem der strikten Subkategorisierung beim Verb
nunmehr mithilfe von Merkmalen besser handhaben. Wir führen dazu ein Merkmal Subkat
(für Subkategorie) mit Zahlen als Merkmalswerten ein. Die Festlegung der Merkmalswerte
erfolgt dabei durch die Phrasenstrukturregeln. Anstelle der alten Regel
(4.) (2)(a) VP →
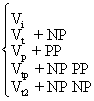
erhalten wir dann:
(4.73) (2)(a) VP →
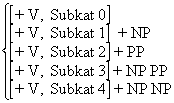
Für [+V, Subkat 0] kann vereinfachend auch V[Subkat 0] oder noch kürzer V[0] geschrieben
werden.
(4.74) (2)(a) VP →
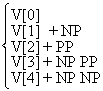
Das Merkmal [Subkat 0] kennzeichnet also intransitive Verben, das Merkmal [Subkat
1] transitive Verben, etc.
Das Lexikon ist dann eine Liste von Wörtern, die neben anderen Informationen auch
eine Merkmalsspezifikation aufweisen, z.B.
run: [+V, Subkat 0]
kick: [+V, Subkat 1]
etc.
Grammatische Funktionen
Strukturelle Ambiguität
Wir haben bereits einige Beispiele von mehrdeutigen Sätzen kennengelernt, d.h. von
Sätzen, die auf verschiedene Weise verstanden werden können. Betrachten wir das
folgende Beispiel:
(4.75.) The visitor watched the girl with the telescope.
Dieser Satz kann auf zweierlei Art und Weise verstanden werden. Man kann dies durch
Paraphrasen wie die folgenden explizit machen:
|
(4.76.)
|
(a) The visitor used the telescope to watch the girl
|
|
|
(b) The visitor watched the girl who had the telescope.
|
In einer Interpretation modifiziert with the telescope die Verbalphrase watched
the girl, im anderen Falle ist sie Modifikation von the girl. Dies
wird weiter bestätigt durch das unterschiedliche Verhalten bei Tests wie die Pseudo-Spaltsatz-Konstruktion
oder die Passivierung.
|
(4.77.)
|
(a) What the visitor watched was [the girl with the telescope]NP
|
|
|
(b) What the visitor watched with the telescope was [the girl]NP
|
|
(4.78.)
|
(a) [The girl with the telescope]NP was watched by the visitor
|
|
|
(b) [The girl]NP was watched with the telescope by the visitor.
|
Die Ambiguität eines Satzes kann einerseits auf der Mehrdeutigkeit einzelner Wörter
beruhen, oder auf der Tatsache, daß ihm verschiedene Strukturbeschreibungen zugeordnet
werden können (strukturelle Ambiguität). Im zur Diskussion stehenden Beispiel besetzt
die Präpositionalphrase [with the telescope]PP verschiedene Positionen
in der syntaktischen Gesamtstruktur: es kann einerseits als unmittelbare Konstituente
der Nominalphrase mit dem Kopf girl analysiert werden, oder andererseits
als unmittelbare Konstituente der Verbalphrase (oder eventuell des ganzen Satzes).
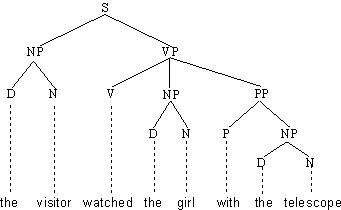
Abb. 4.45.
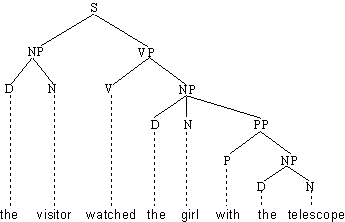
Abb. 4.46.
In Fällen struktureller Ambiguität erkennen wir einen engen Zusammenhang zwischen
der Strukturbeschreibung von Sätzen und der Art und Weise, wie sie verstanden werden.
Wir können die folgende Hypothese aufstellen:
In den bisher diskutierten Beispielen konnten die Ambiguitäten auf der syntaktischen
Ebene erklärt werden. Es gibt jedoch Fälle, in denen die Ambiguität nicht mit den
strukturellen Mitteln, die wir bisher kennengelernt haben (Konstituenz oder Dependenz),
erklärt werden kann. Sehen wir uns dazu das folgende Beispiel genauer an:
(4.79.)
Zur Erklärung der Infinitivkonstruktion wollen wir versuchsweise die folgende Regel
postulieren (INFKOMP = Infinitivkomplement):
(4.80.) INFKOMP → to VP
Die Beispiele (4.79)(a) und (b) können wie folgt repräsentiert werden:
Abb. 4.47.
Abgesehen von den lexikalischen Unterschieden beim Verb (promise vs. persuade)
und der Tatsache, daß Bill im einen Falle ein Dativ, im anderen aber ein
Akkusativ ist, scheinen diese Sätze identische Strukturen aufzuweisen. Eine genauere
Untersuchung zeigt jedoch, daß sie ganz unterschiedlich interpretiert werden. Die
Frage Who does the mowing? muß verschieden beantwortet werden. Im Falle von
Abb. 4.47 (a) ist es John, im anderen Falle ist es Bill. Nun nehmen
die Nominalphrasen John und Bill in diesen Sätzen verschiedene Positionen
ein. John ist eine unmittelbare Konstituente des ganzen Satzes, während Bill
eine unmittelbare Konstituente der Verbalphrase (VP) ist. Wir werden sagen, daß
diese Nominalphrasen in Abhängigkeit von ihrer Position im Satz an verschiedenen
grammatischen Relationen oder grammatischen Funktionen teilhaben. In traditioneller
Redeweise ist John das Subjekt und Bill das Objekt. Was die eingebettete
Verbalphrase to mow the lawn betrifft, können wir sagen, daß sie ein implizites
("mitverstandenes") Subjekt hat, welches im Falle von promise mit
dem Subjekt des übergeordneten Satzes identisch ist, während es im Falle von überreden
mit dessen Objekt übereinstimmt.
Allgemein gesprochen können wir den Begriff Grammatische Funktion wie folgt definieren:
Definition 4.51. grammatische Funktion
Gegeben seien zwei benannte Knoten A und B. Wir definieren eine grammatische Funktion
als eine Relation (A,B), gesprochen "A von B", wobei B das A unmittelbar
dominiert (bzw. A unmittelbare Konstituente von B ist).
In einem gegebenen Phrasenmarker gibt es soviele verschiedene grammatische Funktionen
wie es verschiedene Paare von grammatischen Kategorien (A, B) gibt, zwischen welchen
die Relation der unmittelbaren Dominanz besteht. Einige dieser Funktionen sind aus
der Schulgrammatik vertraut, wie die folgende Aufstellung zeigt.
|
Funktion
|
Funktionsname
|
Struktur
|
|
(NP, S)
|
Subjekt (von)
|
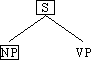
|
|
(VP, S)
|
Prädikat (von)
|
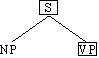
|
|
(NP, VP)
|
Objekt (von)
|
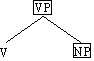
|
|
(NP, PP)
|
Objekt (von)
|
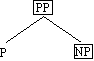
|
|
(AP, NP)
|
Attribut (von)
|
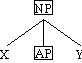
|
|
(X, XP)
|
Kopf (von)
|
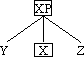
|
In den Phrasenmarkern, welche die Konstituentenstruktur von Sätzen beschreiben,
könnten wir die relevanten grammatischen Funktionen durch zusätzliche Annotationen
in der Form Kategorie:Funktion anzeigen:
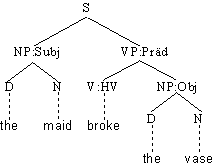
Abb. 4.48.