Merkmalstrukturen
PS-Regeln und Merkmalstrukturen[1]
Wie die letzte Aufgabe des Extemporales am 06.05. gezeigt hat, haben Sie den zur Sitzung zu lesenden Abschnitt Two approaches to morphological rules aus unserem Lehrbuch (Haspelmath & Sims: 40–53, fortan UM) nicht verstanden. Dieses Verständnis brauchen Sie aber, um vieles von dem zu erschließen, was in den nachfolgenden Kapiteln steht. Nachstehend finden sie ein paar vertiefende Informationen zu einigen der im Abschnitt verwendeten Konzepte und der Argumentation.
Phrasenstrukturbäume und -regeln. Bezug: UM 41.
In UM wird ab Seite 41 der morphem-basierte Ansatz zur Erfassung morphologischer Regelhaftigkeiten vorgestellt. Ein wichtiger Punkt der Argumentation bezieht sich auf die Beobachtung, dass es Ähnlichkeiten gibt in der Art und Weise, wie Wörter und Sätze gebildet werden, nämlich wenn diese jeweils als strukturierte Verkettungen von (a) Morphemen und (b) Wörtern gesehen werden. Um diese Analogie zu erfassen, könnte es sich anbieten, morphologische Strukturen und Gesetzmäßigkeiten auf die gleiche Art und Weise zu erfassen, wie syntaktische Strukturen und Gesetzmäßigkeiten, und letzere wurde in Form einer P(hrasen)-S(truktur)-G(rammatik) vorgestellt.
Wie Sie mir mitteilten, hatten Sie von so etwas schon mal in der Einführung gehört, letztlich aber keine Ahnung mehr, worum es dabei geht und was das soll. Die nachstehenden Abschnitte sollen Ihnen diesbezüglich eine kleine, völlig ahistorische Grundlage geben. Wir beginnen mit einem PS-Baum, also etwas, was Sie mit großer Wahrscheinlichkeit auch in der Einführung durchgenommen haben, und das bei Ihnen erfahrungsgemäß eine ganze Reihe von Fragen aufwirft:
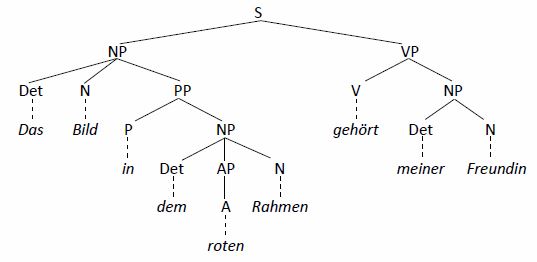
Diese Fragen sind einerseits spezifischer Natur (beispielsweise »warum sind einige Linien gestrichelt, andere durchgezogen?« oder »warum hat ein einzelnes A den Status einer AP?«), beziehen sich aber andererseits ganz allgemein auf die Funktion, die derartige Bäume innehaben: was bringen solche Phrasenstrukturen überhaupt?
Um einen Zugang zu solchen Strukturen zu bekommen, sollten sie zunächst einmal als das gesehen werden, was sie sind: sie sind Träger detaillierter Information darüber, wie ein individueller Satz aufgebaut ist, was also in diesem Satz eine Einheit (=Konstituente, Phrase) darstellt und was sich worauf bezieht.
Die Information darüber, welche Konstituenten im Beispielsatz vorliegen, kann auch in Form eines Klammerausdrucks dargestellt werden:
[[Das Bild [in [dem [roten] Rahmen]]] [gehört [meiner Freundin]]]
Diese Struktur, wie auch der Baum, stellt also eine Aussage über die Konstituenz des Satzes dar. Solche Aussagen müssen, um wissenschaftlichen Standards zu genügen, in irgendeiner Form überprüfbar sein, und genau zu diesem Zweck können die »Verfahren zur Satzanalyse« dienen, die Ihnen wahrscheinlich auch in der Einführung näher gebracht worden sind: dass beispielsweise [meiner Freundin] den Status einer Konstituente hat, kann durch Pronominalisierung belegt werden: Das Bild in dem roten Rahmen gehört ihr; ebenso wie die Aussage, dass das Bild keinen Konstituentenstatus hat: *Es in dem roten Rahmen gehört ihr.
Im Vergleich zum Klammerausdruck enthält der Baum aber noch weitere Information, nämlich darüber, zu welcher jeweiligen Klasse die Konstituenten gehören.[2] Dabei können wir unterscheiden zwischen den phrasalen Kategorien, also Konstituentenklassen wie NP, VP etc. einerseits und lexikalischen Kategorien, also Wortklassen wie Det, V, P andererseits. Die gestrichelten Linien im PS-Baum drücken dabei im Wesentlichen die »ist-ein«-Beziehung aus: das Wort Freundin ist ein N, das Wort in ist ein P (von oben nach unten betrachtet kann man natürlich auch sagen: N ist realisiert durch Freundin; P ist realisiert durch in). Die durchgezogenen Linien dagegen bedeuten soviel wie »ist unmittelbare Konstituente von« (bzw. – wieder von oben nach unten – »dominiert unmittelbar«).[3]
Was in vielen Einführungen fehlt, ist der ganz zentrale Hinweis darauf, dass wir durch die Verwendung von Klassen die Ebene der inviduellen »Einzelinstanzen«, hier also des individuellen Satzes, verlassen können, und somit Aussagen treffen, die auf eine Vielzahl konkreter Erscheinungen zutreffen. Sie müssen immer im Hinterkopf behalten, dass die Zahl der möglichen Sätze einer natürlichen Sprache unendlich ist, wir also ein System brauchen, mit dem wir das, was wir beobachten, generalisiert beschreiben können. Genau zu diesem Zweck dienen Klassen, und zwar nicht nur in der Syntax, sondern auf allen Ebenen der Sprachbeschreibung – auf diesem Punkt reiten wir ja seit dem Phonologie-Seminar gnadenlos rum.
Als die in diesem Text vorgestellte Art der syntaktischen Beschreibung am Ende der 50er und in den 60er Jahren des letzten Jahrhunderts eingeführt wurde, war das primäre Ziel eben nicht, einzelne, wahllos herausgepickte Beispielsätze zu analysieren: Ziel ist es gewesen, die syntaktischen Strukturen einer Sprache umfassend generalisiert und präzise zu erfassen. Diese Generalisierung basiert dann allerdings auf der genauen Analyse konkreter Sätze bzw. ist daraus abgeleitet. Wenn Sie diese Information nicht haben, sind Ihre Fragezeichen bezüglich des Nutzen von Bäumen durchaus nachvollziehbar.
In den weiteren Entwicklungsstufen dieser Art von Syntaxbeschreibung hat sich sehr viel getan. Bäume wie in den Abbildungen Abbildung 1 oder Abbildung 4 weiter unten werden Sie heute kaum noch finden, viele der in modernen Ansätzen verwendeten Kategorien werden in diesem Text gar nicht angesprochen und zahlreiche Modifikationen des Gesamtmodells fallen unter den Tisch. Wenn Sie sich intensiver mit Syntax beschäftigten, würden Sie m.a.W. vieles von dem, was in diesem und ähnlichen Texten steht, revidieren müssen (womit Sie dann im Grunde die wissenschaftshistorische Entwicklung nachzeichnen würden).
Das, worum es mir geht, und was über die Zeit konstant geblieben ist, ist aber folgendes: Syntaxbäume zeigen genau an, was in einem Satz zusammengehört und was wovon abhängt. Über die Verwendung von Kategorien (egal ob lexikalisch oder phrasal) stellen Syntaxbäume darüberhinaus stets eine Generalisierung über potentiell mögliche Strukturen dar. Das war in den 50er Jahren so und ist es heute auch noch, egal, wie unterschiedlich diese Strukturen selber ausgestaltet sein mögen.
Deutlich wird der generalisierende Effekt von Klassen in der Syntax, wenn wir uns einmal ansehen, welche Elemente jeweils mögliche Kandidaten sind, um die Klassen zu repräsentieren. Wenn wir uns in Baumgraph bzw. Klammerausdruck 1 ausschließlich auf die Struktur konzentrieren, also
[[[ ]Det[ ]N [[ ]P [[ ]Det [[ ]A]AP[ ]N]NP]PP]NP [[ ]V [[ ]Det[ ]N]NP]VP]S
so können wir mit entsprechend ausgebautem Lexikon bereits zahllose weitere Sätze beschrieben, die dieselbe Struktur aufweisen, schlichtweg dadurch, dass wir die einzelnen Wörter des Satzes durch andere Wörter substituieren, die derselben Klasse angehören:
Der Hund mit dem riesigen Gebiss verängstigt die Kinder. | Der Maserati von meinem Vater gefällt der Damenwelt. | Eine Frau mit blonden Haaren erregte seine Aufmerksamkeit. | Die Bluse mit weißen Punkten entzückte meine Mutter usw.
Für die Bildung von lexikalischen Kategorien, sprich Klassen von Lexemen, ist – Sie erinnern sich – unter anderem deren Distribution relevant: Wörter wie Hund, Maserati, Haaren, Bluse, Bild einerseits und gehört, gefällt, verängstigt, erregte, entzückte andererseits usw. haben die gleiche Verteilung und können in einer Klasse gruppiert werden.
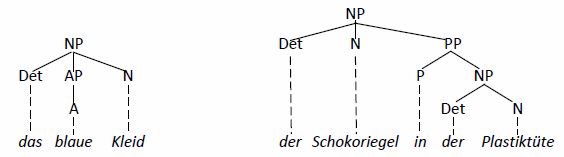
Genau das gleiche Prinzip kann für die Konstituentenklassen angewendet werden. So hat z.B. die NP [Das Bild in dem roten Rahmen] die gleiche Distribution wie die folgenden Phrasen:
gehört meiner Freundin
Die Segmente sind im gleichen Kontext füreinander austauschbar und können einer Klasse zugeordnet werden. Offenkundig dabei ist, dass diese Klassen intern durchaus unterschiedlich strukturiert sein können. So setzen sich die NP jeweils wie folgt zusammen:
- [Sie]NP
- [Der Schokoriegel [in [der Plastiktüte]NP]PP]NP
- [Die Katze]NP
- [Die [roten]AP Schuhe]NP
- [Dieses [ziemlich dicke]AP Kind]NP
- [Das Buch [das ich gestern hier liegen gelassen habe]Rel-S]NP
Das, was Beispiele 1-6 neben ihrer Distribution verbindet (im Grunde die Begründung für ihre Verteilung), ist der Umstand, dass sie allesamt einen nominalen Kopf aufweisen.[4]
Wenn wir – ausschließlich auf der Basis der hier verwendeten Beispiele – eine Beschreibung möglicher NP im Deutschen formulieren wollten, so sähe diese in etwa wie folgt aus:
eine möglich NP des Deutschen konstitiuiert sich (»setzt sich zusammen aus«):
- entweder nur einem Personalpronomen (sie) oder
- aus einem Determinator und einem Nomen (die Katze, meiner Freundin) oder
- aus einem Determinator, einer AP und einem Nomen (das blaue Kleid, dieses ziemlich dicke Kind) oder
- aus einem Determinator, einem Nomen und einer PP (der Schokoriegel in der Plastiktüte) oder
- aus einem Determinator, einem Nomen und einem Relativsatz (das Buch, das ich gestern hier liegen gelassen habe)
Das Gleiche können wir in Form einer PS-Regel ausdrücken, die die folgende Form hätte:[5]
�
Diese Regel ist also nichts anderes als eine verallgemeinerte Beschreibung über die möglichen Strukturen der Nominalphrase im Deutschen. Sie macht eine Aussage darüber, welche potentiellen Formen eine NP haben und wie sie intern strukturiert sein kann.
Natürlich müssten wir, um das Ganze zu vervollständigen, auch noch angeben, wie denn genau die Strukturen von AP, PP und Relativsatz aussehen könnten, auf die wir in der NP-Regel Bezug nehmen. An dieser Stelle sollte nun auch klar werden, wieso ein einzelnes Adjektiv den Status einer AP hat. Sehen Sie sich dafür die folgenden NP an:
- ein trauriger Mann
- ein sehr trauriger Mann
- ein über den Tod seines Hundes trauriger Mann
- ein über den Tod seines Hundes sehr trauriger Mann
Wenn wir das einzelne Adjektiv nicht als Phrase ansehen, müssten wir die NP in 7-10 in zwei verschiedenen NP-Regeln erfassen, nämlich:
- NP → Det A N
- NP → Det AP N
Das alleinstehende Adjektiv hat aber dieselbe Verteilung wie die Kombination aus Adjektiv und Adverb (wie in 8), Adjektiv und PP (wie in 9) und Adjektiv, Adverb und PP (wie in 10). Dieser Umstand kommt in den Regeln nicht zur Geltung, sie wären – um es mit UM:6 auszudrücken, nicht elegant. Der Unterschied zwischen 7-10 liegt nicht darin, dass die NP verschieden realisiert sind – er liegt an den vier unterschiedlichen Realisierungsformen der AP, und genau die werden ausgedrückt, wenn die Strukturen wie folgt in Regeln erfasst werden:
- NP → Det AP N
- AP → (PP) (Adv) A
Genau diese Erkenntnis ist letztendlich verantwortlich dafür, dass das Adjektiv rotem in Abbildung 1: PS-Struktur der Klasse AP zugewiesen ist: hier wurde bereits generalisiert.
Um nun auf unsere Einstiegsfrage zurückzukommen, sprich die Frage danach, wozu ein PS-Baum wie in Abbildung 1: PS-Struktur dient.: Zunächst zeigt er die interne Struktur des Satzes Das Bild in dem roten Rahmen gehört meiner Freundin an, indem er die darin vorliegenden (Dependenz- und) Konstituenzbeziehungen detailliert auflistet. Dieses erfolgt per genauer Angabe darüber, welcher Kategorie die im Satz vertretenen Elemente (Wörter und Konstituenten) jeweils angehören. Der Erkenntnis, dass Adjektive auf der phrasalen Ebene den Status von AP haben, ist dabei bereits Rechnung getragen.
Darüberhinaus aber kann der Satz als ein Teilbaustein für die Verallgemeinerung der Strukturen des Deutschen betrachtet werden: er kann, wenn Sie so wollen, als eine Art Muster oder Template für zahlreiche verschiedene Sätze fungieren. Für den konkreten Satz in Abbildung 1: PS-Struktur erhalten wir die folgenden, generalisierten Aussagen über das Deutsche:
- SP → NP VP (Das Bild in dem roten Rahmen gehört meiner Freundin)
- NP → Det N PP (das Bild in dem roten Rahmen)
- NP → Det AP N (dem roten Rahmen)
- NP → Det N (meiner Freundin)
- AP → A (roten)
- VP → V NP (gehört meiner Freundin)
- PP → P NP (in dem roten Rahmen)
Die NP-Regeln können wie folgt zusammengefasst werden:
- NP → Det (AP) N (PP)
Bei entsprechendem Lexikon würde diese Mini-Grammatik, die auf der Analyse eines Satzes beruht, bereits unzählige Sätze des Deutschen beschreiben. Werden mehr Sätze hinzugenommen und das Regelset auf diese Weise erweitert, entstünde peu à peu eine Grammatik der deutschen Syntax.
Merkmalstrukturen. Bezug: UM 36, 43, 45.
Ein weiteres Konzept, das in UM nicht explizit eingeführt werden kann, aber verwendet wird, sind Merkmalsstrukturen für die Darstellung linguistischer Objekte wie z.B. Morpheme, Wörter oder Sätze. Dieser Notationsform werden Sie in zahlreichen neueren Arbeiten begegnen, darum hier ein wenig Hintergrund.
Der erste Teil der Sitzung über Wortarten vom 29. 04. stand unter der Überschrift »Objekte, Merkmale und Klassen – elementar«. Ausgehend vom Vergleich der Objekte ■ und ● wurde festgestellt, dass diese über eine Matrix der folgenden Art beschrieben und verglichen werden können:
|
|
Merkmal |
|
|
Objekt |
Attribut |
Wert |
|
● |
Farbe |
rot |
|
Form |
kreisförmig |
|
|
■ |
Farbe |
blau |
|
Form |
quadratisch |
|
Verallgemeinert gilt, dass
- Objekte entweder physische Entitäten oder begriffliche Einheiten sind,
- Attribute allgemeine Eigenschaften sind, die mit Objekten assoziiert werden. Form und Farbe sind typische Attribute physischer Objekte,
- der Wert eines Attributs die spezifische Beschaffenheit oder Ausprägung eines Attributs kennzeichnet,
- Attribut und Wert zusammengenommen ein Merkmal des Objekts beschreiben.
Ein gemeinsames Attribut der beschriebenen Objekte kann als Tertium Comparationis (lat.: 'das Dritte des Vergleichs') gesehen werden. Die Information über die beiden Objekte der Merkmalsmatrix in Abbildung 5 können nun individuell repräsentiert werden, indem die Merkmale eines Objekts in eckigen Klammern neben (oder – wie in UM – unter) diesem aufgeführt werden:
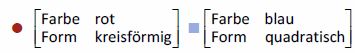
Genau auf diese Weise sind die Merkmalsstrukturen für Morpheme bzw. Wörter in UM aufgebaut, wobei dort allerdings zu berücksichtigen ist, dass nur der jeweilige Wert aufgeführt ist. Nachstehend sehen Sie eine Merkmalstruktur für das Wort bag, einmal in der UM-Fassung; daneben mit voll spezifizierten Attributbezeichnung. Die UM-Fassung kann als Kurzform davon betrachtet werden:

Derartige Strukturen werden Sie in zahlreichen neueren Ansätzen finden, da sie sich als recht flexibles Instrument für die Verarbeitung von linguistischer Information erwiesen haben. Dieses ist u.a. dadurch gegeben, dass Merkmalsstrukturen auch
- komplex bzw. verschachtelt sein und
- Variablen enthalten können, die wiederum einen größeren Generalisierungseffekt haben.
Diese beiden Punkte können gut anhand der nachstehenden Nominalphrasen illustriert werden:
- der Mann
- die Frau
- das Kind
- des Kindes
Wenn wir uns eine Mini PS-Grammatik nach obigem Muster für diese Phrasen vorstellen, so könnte diese wie folgt aussehen:
Regel: NP → Det N
Lexikon: N: {Mann, Frau, Kind, Kindes}
Lexikon:Det: {der, die, das, des}
Leider würde diese Grammatik aber auch die Ketten *das Frau, *die Mann, *dem Frau, *der Kindes, *des Frau usw. als grammatisch anerkennen, da wir weder in der Regel noch im Lexikon in irgendeiner Form berücksichtigt haben, dass das Genus-Attribut der einzelnen Wörter unterschiedliche, d.h. nicht kompatible Wert hat: der und Mann als Maskulina, die und Frau als Feminina, das und Kind als Neutra; ferner haben wir auch noch Unterschiede im Attribut Kasus: der als Nominativ, dem als Dativ, die als Nominativ, des als Genitiv usw.
Ganz traditionell würden wir sagen, dass Determinator und Nomen mit Bezug auf diese Attribute sowie das Numerus-Attribut kongruieren, d.h. dieselben Werte aufweisen müssen. Genau dieses können wir ausdrücken, indem wir ein Mermkal kongruenz einführen, das selber wieder Attribut-Wert-Paare umfasst. Dieses könnte z.B. für Kindes und des die folgende Formen haben:
Diese Art Struktur bringt uns schon weiter, da wir jetzt Angaben über die Kombinatorik der einzelnen Formen mit Information über ihre Kongruenzmerkmale versehen können. Erst der Einsatz von Variablen aber lässt uns verallgemeinert ausdrücken, was Sache ist: was wir sagen wollen, ist ja, dass es letztlich egal ist, welchen spezifischen Wert das Attribut kongruenz bei Nomen und Determinator aufweist – Hauptsache ist, dass sie übereinstimmen. Das können wir ausdrücken, indem wir eine Regel wie (informell) die folgende postulieren:
NP → Det[kongruenz: X] N[kongruenz: X]
bei der die konkreten Werte des Kongruenz-Attributes durch eine Variable repräsentiert sind, die – und das ist der Knackpunkt – für Determinator und Nomen auf einander abbildbar sein müssen. Nach dieser Regeln könnten Kindes und des miteinander verkettet werden; Kindes und der, die oder das hingegen nicht.
In dem gerade genannten Beispiel kommen Variablen in Merkmalsstrukturen zum Einsatz, um Kongruenzbeziehungen generalisiert zu beschreiben. In UM kommen Variablen in Merkmalstrukturen zum Einsatz, um morphologische Muster generalisiert zu beschreiben. Grundlage dafür ist das Wortschema (vgl. UM: 46), bei dem es darum geht, bestimmte, jeweils bei mehreren Wörtern auftretende Form/Bedeutungskorrelationen generalisiert zu beschreiben. Ein an PS-Strukturen orientierter, morphembasierter Ansatz als Grundlage für die Bildung des Plurals im Englischen könnte die folgenden Regeln und entsprechenden Bäume umfassen (WF = Wortform):
- WF[PLURAL] → Stamm FS[PLURAL]
- Stamm → {bag, dog, goal}
- FS[PLURAL] → {-s}

Im wortbasierten Ansatz dagegen wird eine Beziehung zwischen dem generalisierten Singular- und Pluralschema postuliert (der Doppelpfeil bedeutet soviel wie »korrespondiert mit«, »kann abgebildet werden auf«):
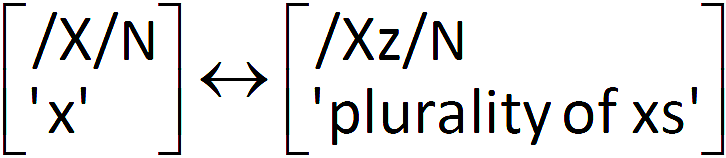
Ein Vorteil dieser Beschreibung morphologischer Regelhaftigkeiten ist darin zu sehen, dass sie nicht in dem Sinne gerichtet wäre, dass komplexere Formen sukkzessive aus einfacheren Formen aufgebaut werden. Dieses führt z.B. im Falle der Backformation (vgl. UM: 48) zu Problemen. Außerdem treten im wortbasierten Ansatz für den Bereich »nicht konkatenative Morphologie« nicht die Schwierigkeiten auf, die bei einem morphembasierten Ansatz zu beobachten sind. Andererseits stellt der morphembasierte Ansatz für viele Fälle eine elegantere, da generalisiertere Möglichkeit dar, morphologische Regelhaftigkeiten verallgemeinert zu beschreiben.
In Kapitel 4 von UM, Lexicon, werden diese Punkte erneut thematisiert.
Anmerkungen
100Vieles aus des ersten Teil dieses Textes stammt aus »Phrasenstrukturbäume und -regeln«, der für das letztsemestrige Syntaxseminar verfasst wurde.
200Auch
diese Information könnten wir
in Form eines Klammerausdrucks notieren, was die Sache aber ziemlich unübersichtlich
werden lässt:
[[[Das]Det [Bild]N [[in]P
[[dem]Det
[[roten]A]AP[Rahmen]N]NP]PP]NP
[[gehört]V [[meiner]Det
[Freundin]N]NP]VP]S
300Viele Autoren sind hier etwas schlampig und verwenden ausschließlich durchgezogene Linien in ihren Baumgraphen. Das mag durch spätere Entwicklungen in der Syntaxtheorie begründet sein, in denen die Grenze zwischen lexikalischen und phrasalen Kategorien immer mehr verwischt, aber so, wie wir die Sache angehen, sollte man hier schon sauber notieren, was was ist.
400Über das, was in der Syntax ein »Kopf« ist, und dass es zu der hier vorgestellten Analyse durchaus Alternativen gibt, werden Sie noch mehr im Syntax-Seminar erfahren.
500Wie Ihnen noch aus der Phonologie bekannt sein sollte, umfassen geschweifte Klammern Alternativen; runde Klammern drücken Fakultativität aus.